


网络爬虫到底是什么?一篇文章理清核心知识点(一)
在信息爆炸的互联网时代,网页中蕴藏着海量有价值的数据 —— 从行业动态、商品信息到学术资料,若手动收集这些数据,不仅效率低下,还容易出错。而网络爬虫作为自动化获取网页数据的核心工具,能帮我们快速抓取、整理目标信息,成为数据分析、科研攻关、业务决策的 “得力助手”。本文将从基础概念入手,带你认识常用爬虫库、掌握 robots.txt 规则,再通过 requests 库的 get ()、post () 函数实操,一步步解锁网页数据获取技巧,即使是编程新手也能轻松上手~
一、网络爬虫的介绍
1.网络爬虫库
网络爬虫通俗来讲就是使用代码将HTML网页的内容下载到本地的过程
| urllib库 | 标准库,包含大量爬虫功能,但代码编写略微复杂 |
| request库 | 第三方库,需要下载,包含urllib库的功能并且使用起来更加简洁、方便 |
| scrapy库 | 第三方库,需要下载,适用于专业应用程序开发的爬虫库 |
| selenium库 | 第三方库,驱动计算机中的浏览器执行相关命令,无需用户手动操作,用于自动驱动浏览器实现办公自动化和Web应用程序测试 |
2.robots.txt规则
不是网站中的所有信息都可以被爬取,也不是所有网站都允许被爬取
大部分网站的根目录中都存在一个robots.txt文件
该文件用于声明次网站中禁止访问的url和可以访问的url
只需在网站域名后加上/robots.txt即可读取此文件内容
例如:

二、requests库和网页代码
1.requests库安装
在命令提示符窗口输入:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
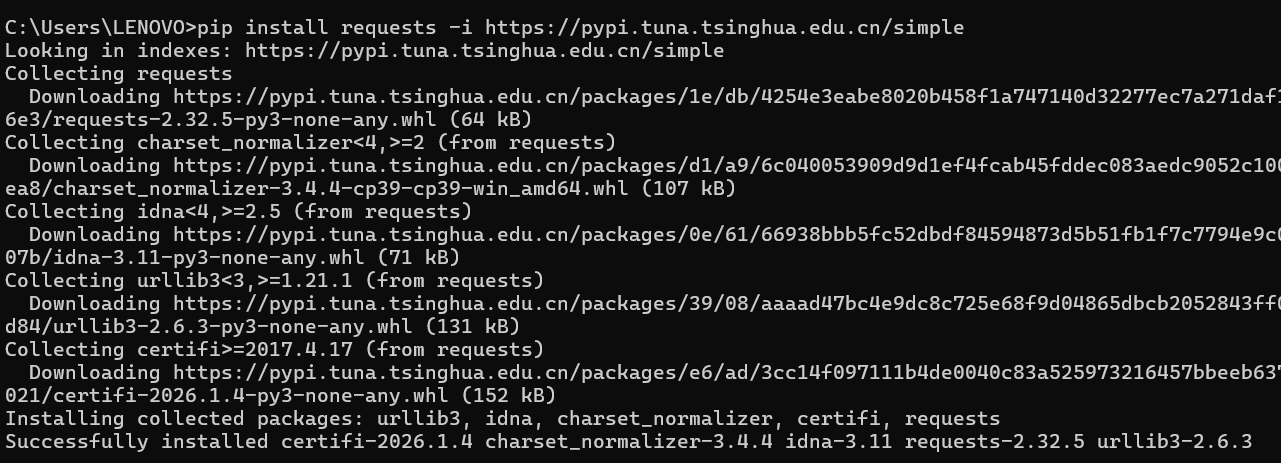
出现'Successful'就下载成功了
2.网页源代码
在使用网页时,按F12键就可以出现网页源代码界面

三、获取网页资源
1.get()函数
使用形式:
get(url, params=None, **kwargs)
url:表示需要获取的HTML网址
params:表示可选参数,以字典的形式发送信息
**kwargs:表示请求采用的可选参数
返回值:返回一个由类Response创建的对象
例如:
''' 设置编码 '''
import requests
r = requests.get('https://www.baidu.com')
r.encoding = r.apparent_encoding
print(r.text)

get()搜索信息
例如:
'''搜索信息'''
import requests
r = requests.get('https://www.ryjiaoyu.com//search?keyword=python')
print(r.text)
get()添加信息
例如:
'''添加信息'''
import requests
info = {'keyword': 'excel'}
r = requests.get('https://www.bilibili.com/search', params=info)
print(r.url)
print(r.text)
2.返回Response对象
Response包含的属性有status_code、headers、url、encoding、cookies等等
status_code(状态码):当获取一个HTML网页时,网页所在的服务器会返回一个状态码
例如:
'''状态码'''
import requests
r = requests.get('https://www.baidu.com')
print(r.status_code) # 状态码
print(r.headers) # 响应的头部信息,包括服务器类型、内容类型、内容长度等
print(r.url) # 响应的最终url位置
print(r.encoding) # 访问r.text时使用的编码
print(r.cookies) # 服务器返回的文件
if r.status_code == 200:
print(r.text)
else:
print('本次访问失败')
header(响应头):服务器返回的附加信息
url:响应的最终url位置
encoding:访问r.text时使用的编码
cookies:服务器返回的文件
设置编码
例如:
''' 设置编码 '''
import requests
r = requests.get('https://www.baidu.com')
r.encoding = r.apparent_encoding
print(r.text)

小项目实例:实现处理或取得网页信息
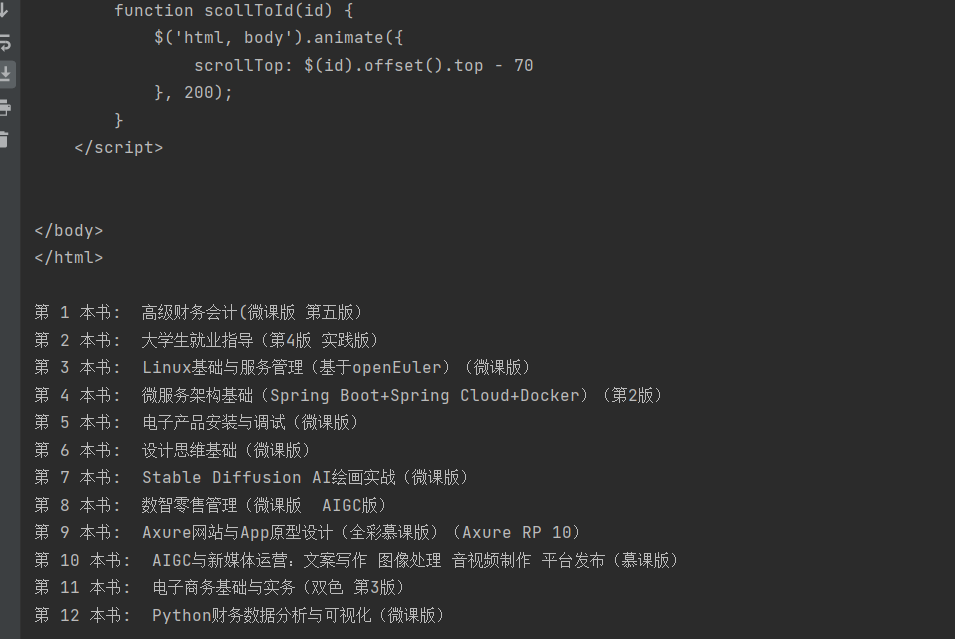
某网页中上架了新书,需要requests库爬取当前网页中所有新书的书名
'''项目实现处理或取得网页信息'''
import requests
import re
r = requests.get('https://www.ryjiaoyu.com/tag/details/7')
print(r.text)
result = re.findall(r'title="(.+)">(.+)', r.text)
for i in range(len(result)):
print('第',i+1,'本书: ', result[i][1])
四、post()函数
使用形式:
post(url, data=None, json=None, **kwargs)
url:表示网站url
data:表示需要发送的数据对象,可以为字典、元组、列表、字节数据或文件
json:表示需要发送的数据对象
**kwargs:表示请求采用的可选参数
返回值:使用post()函数后返回一个Response对象
例如:
'''post 请求'''
import requests
d = {'OldPassword': '123python', 'ConfirmPassword': '123456python'}
r = requests.post('https://account.ryjiaoyu.com/change-password', data=d)
print(r.text)
import requests
d = {'Password': 'Python123', 'Email': '15556520641'}
r = requests.post('https://account.ryjiaoyu.com/log-in', data=d)
print(r.text)
通过本文的讲解,相信你已经对网络爬虫有了清晰的认知,也掌握了 requests 库获取网页资源的核心方法 —— 从简单的网页源码爬取,到带参数的搜索、数据提交,再到实际项目中提取目标信息,每一步都是爬虫入门的关键积累。当然,爬虫世界还有更多进阶技巧等待探索,比如应对反爬机制、使用正则表达式精准解析数据、结合其他库实现更复杂的爬取需求等。希望这篇文章能成为你开启爬虫之旅的 “敲门砖”,后续不妨尝试针对自己感兴趣的场景(如爬取电影评分、新闻资讯等)动手实践,在实操中不断提升技能。如果在爬取过程中遇到问题,也可以随时复盘知识点或查阅官方文档,祝你在数据获取的道路上越走越远,解锁更多互联网数据的隐藏价值!







