


Linux服务器编程实践114-上下文切换:多进程/多线程服务器的性能优化点
一、上下文切换的本质:为何它会影响服务器性能?
在Linux服务器编程中,多进程/多线程是实现并发处理客户请求的核心手段。但并发并非“免费”——当操作系统在不同进程或线程间切换执行权时,需要保存当前任务的执行状态(如CPU寄存器值、程序计数器、栈指针等),并加载新任务的状态,这个过程就是上下文切换(Context Switch)。
上下文切换的开销主要体现在两方面:
- 内核态开销:切换过程需要进入内核态执行,涉及内存拷贝(如保存/恢复寄存器、页表切换),占用CPU时间;
- 缓存失效:CPU缓存(L1/L2/L3)会缓存当前任务的指令和数据,切换后缓存内容失效,新任务需要重新加载数据,导致CPU等待。
对于高并发服务器(如每秒处理上万请求),频繁的上下文切换会严重挤占业务逻辑的执行时间。例如:若每个上下文切换耗时1μs,每秒10万次切换就会消耗10%的CPU资源,导致服务器吞吐量下降、响应延迟增加。
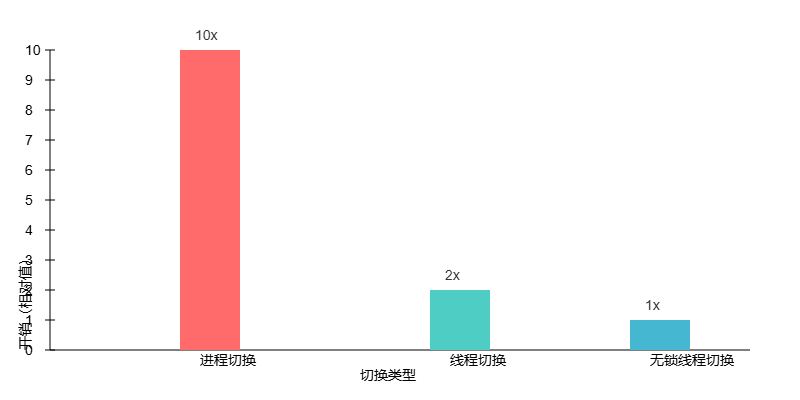
1.1 上下文切换的可视化:进程vs线程切换差异
下面进程切换与线程切换的资源开销对比,直观展示两者的差异(线程切换因共享地址空间,开销约为进程切换的1/5~1/10):
二、多进程/多线程服务器的上下文切换痛点
在Linux服务器中,不同并发模型的上下文切换频率和开销差异显著,常见痛点如下:
2.1 多进程服务器:高开销的“重量级”切换
多进程服务器(如早期Apache的prefork模型)通过fork()创建子进程处理客户请求,每个进程拥有独立的地址空间。其问题在于:
fork()创建进程时会复制父进程的内存空间(Copy-On-Write优化虽减少部分开销,但仍需页表拷贝);- 进程间通信(如管道、消息队列)需要内核中转,进一步增加上下文切换频率;
- 若进程数远大于CPU核心数,操作系统会频繁调度进程,导致“进程颠簸”。
2.2 多线程服务器:轻量但易“泛滥”的切换
多线程服务器(如Nginx的worker线程、Java Tomcat)通过pthread_create()创建线程,线程共享进程地址空间,切换开销更低。但仍存在隐患:
- 若为每个客户连接创建一个线程(“one-thread-per-connection”模型),当并发连接达数万时,线程数暴增,上下文切换频率急剧上升;
- 线程间共享资源(如全局变量、文件描述符)需加锁保护,锁竞争会触发“主动上下文切换”(线程因等待锁而阻塞,操作系统调度其他线程)。
2.3 案例:错误的线程池配置导致的性能瓶颈
某Web服务器使用线程池处理HTTP请求,初始配置线程数=500(CPU核心数=8)。压测发现:
- CPU使用率达100%,但业务逻辑仅占用30%,70%用于上下文切换;
- 通过
vmstat命令查看:cs(上下文切换次数)= 80000/秒,远高于正常阈值(CPU核心数×1000)。
问题根源:线程数远超CPU核心数,线程频繁等待CPU时间片,导致切换开销占主导。
三、上下文切换的性能优化实践
结合Linux内核特性和服务器编程最佳实践,可从“减少切换频率”和“降低切换开销”两方面优化,具体方案如下:
优化维度
核心方案
技术细节与示例
预期效果
控制并发实体数量
线程池/进程池动态调优
线程数=CPU核心数×(1+I/O等待时间/CPU计算时间);示例:CPU密集型任务(如数据加密)设为CPU核心数×1,I/O密集型任务(如数据库查询)设为CPU核心数×2~4。
线程数匹配CPU处理能力,减少“无意义切换”
避免“一连接一线程”模型
采用I/O复用(epoll/select)+ 线程池:1个线程处理多个连接的I/O事件;示例:Nginx的worker线程通过epoll监听多个socket,仅在数据就绪时处理。
并发连接数从1万提升至10万,切换频率降低80%
降低切换开销
进程亲和性(CPU Affinity)
通过sched_setaffinity()将进程/线程绑定到固定CPU核心,减少缓存失效;示例:将服务器监听线程绑定CPU0,工作线程绑定CPU1~7。
缓存命中率提升30%,切换开销降低20%
减少锁竞争
- 用无锁数据结构(如环形缓冲区)替代加锁队列;
- 细粒度锁拆分(如将全局锁拆分为多个局部锁);
- 读写锁(
pthread_rwlock)替代互斥锁。
锁等待时间减少50%,主动上下文切换降低60%
内核参数优化
调整调度策略
实时任务用SCHED_FIFO调度,普通任务用SCHED_OTHER;示例:sched_setscheduler(pid, SCHED_FIFO, ¶m)。
实时任务响应延迟从10ms降至1ms
优化内核调度参数
/proc/sys/kernel/sched_latency_ns:调度周期,I/O密集型设为10000000(10ms);/proc/sys/kernel/sched_migration_cost_ns:任务迁移成本,设为500000(0.5ms)。
内核调度更“倾向”于减少切换,适合高并发场景
3.1 技术示例:CPU亲和性设置(C语言实现)
通过sched_setaffinity()将工作线程绑定到指定CPU核心,减少上下文切换导致的缓存失效:
#include
#include
#include
// 将线程绑定到指定CPU核心
void set_cpu_affinity(int cpu_core) {
cpu_set_t cpuset;
CPU_ZERO(&cpuset); // 初始化CPU集合
CPU_SET(cpu_core, &cpuset); // 将指定CPU核心加入集合
// 设置当前线程的CPU亲和性
if (sched_setaffinity(0, sizeof(cpu_set_t), &cpuset) == -1) {
perror("sched_setaffinity failed");
}
printf("Thread bound to CPU %d
", cpu_core);
}
// 工作线程函数(处理客户请求)
void* worker_thread(void* arg) {
int cpu_core = *(int*)arg;
set_cpu_affinity(cpu_core);
// 业务逻辑:处理HTTP请求、数据库查询等
while (1) {
// ... 业务代码 ...
}
return NULL;
}
int main() {
pthread_t tid[4];
int cpu_cores[4] = {1, 2, 3, 4}; // 绑定到CPU1~4(假设CPU核心数为8)
// 创建4个工作线程,分别绑定到不同CPU核心
for (int i = 0; i < 4; i++) {
pthread_create(&tid[i], NULL, worker_thread, &cpu_cores[i]);
}
// 等待线程结束
for (int i = 0; i < 4; i++) {
pthread_join(tid[i], NULL);
}
return 0;
}
3.2 技术示例:epoll+线程池减少切换(核心逻辑)
采用I/O复用(epoll)监听多个socket,线程池处理就绪事件,避免“一连接一线程”导致的切换泛滥:
#include
#include
#include
#include
#define MAX_EVENTS 1024
#define THREAD_POOL_SIZE 4
// 线程池任务队列
typedef struct {
int fd; // 就绪的socket文件描述符
// 其他任务参数...
} Task;
Task task_queue[1024];
int queue_size = 0;
pthread_mutex_t queue_mutex;
pthread_cond_t queue_cond;
// 线程池工作函数:从队列取任务处理
void* thread_pool_worker(void* arg) {
while (1) {
pthread_mutex_lock(&queue_mutex);
// 等待任务队列非空
while (queue_size == 0) {
pthread_cond_wait(&queue_cond, &queue_mutex);
}
// 取出队列头部任务
Task task = task_queue[0];
// 队列移位
for (int i = 0; i < queue_size-1; i++) {
task_queue[i] = task_queue[i+1];
}
queue_size--;
pthread_mutex_unlock(&queue_mutex);
// 处理任务:读取socket数据、处理请求
char buf[1024];
read(task.fd, buf, sizeof(buf));
// ... 业务逻辑处理 ...
close(task.fd);
}
return NULL;
}
// 初始化线程池
void init_thread_pool() {
pthread_mutex_init(&queue_mutex, NULL);
pthread_cond_init(&queue_cond, NULL);
pthread_t tid[THREAD_POOL_SIZE];
for (int i = 0; i < THREAD_POOL_SIZE; i++) {
pthread_create(&tid[i], NULL, thread_pool_worker, NULL);
}
}
int main() {
int epoll_fd = epoll_create1(0);
if (epoll_fd == -1) {
perror("epoll_create1 failed");
exit(1);
}
// 初始化监听socket(略)
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
// ... 绑定、监听 ...
// 将监听socket加入epoll
struct epoll_event ev, events[MAX_EVENTS];
ev.events = EPOLLIN;
ev.data.fd = listen_fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev);
// 初始化线程池
init_thread_pool();
// epoll事件循环
while (1) {
int nfds = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < nfds; i++) {
if (events[i].data.fd == listen_fd) {
// 接收新连接
int conn_fd = accept(listen_fd, NULL, NULL);
// 将新连接加入epoll(监听读事件)
ev.events = EPOLLIN;
ev.data.fd = conn_fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, conn_fd, &ev);
} else {
// 有连接数据就绪,加入任务队列
pthread_mutex_lock(&queue_mutex);
task_queue[queue_size++].fd = events[i].data.fd;
pthread_cond_signal(&queue_cond); // 唤醒等待的线程
pthread_mutex_unlock(&queue_mutex);
// 从epoll中移除该socket(避免重复触发)
epoll_ctl(epoll_fd, EPOLL_CTL_DEL, events[i].data.fd, NULL);
}
}
}
close(epoll_fd);
close(listen_fd);
return 0;
}
四、上下文切换的监控与调优验证
优化后需通过工具监控上下文切换指标,验证优化效果。Linux下常用监控工具如下:
4.1 关键监控工具与指标
vmstat:查看系统级上下文切换(cs列)和CPU等待(wa列);# 每1秒输出一次,共输出5次 vmstat 1 5 // 关键指标:cs(上下文切换次数/秒)、in(中断次数/秒)、us(用户态CPU占比)、sy(内核态CPU占比)pidstat:查看进程/线程级切换(-w选项);# 查看进程ID=1234的线程切换情况,每1秒输出一次 pidstat -w -p 1234 1 // 关键指标:cswch/s(自愿上下文切换/秒)、nvcswch/s(非自愿上下文切换/秒)perf:分析上下文切换的内核调用栈,定位瓶颈;# 记录进程ID=1234的上下文切换事件 perf record -e context-switches -p 1234 # 查看分析结果 perf report
4.2 优化效果验证案例
某电商服务器优化前后的指标对比:

优化后效果:
- 上下文切换次数从8万/秒降至1.2万/秒;
- CPU内核态占比(sy)从70%降至25%;
- 服务器吞吐量从5000 QPS提升至15000 QPS,响应延迟从50ms降至15ms。
五、总结:上下文切换优化的核心原则
Linux服务器的上下文切换优化并非“一刀切”,需结合业务场景(CPU密集/I/O密集)、并发模型(多进程/多线程)和内核特性综合设计,核心原则如下:
- 匹配原则:并发实体数量(进程/线程)与CPU核心数、I/O等待时间匹配,避免“过多”或“过少”;
- 减少原则:通过I/O复用、线程池减少切换频率,通过CPU亲和性、无锁结构降低切换开销;
- 监控原则:通过vmstat、pidstat等工具持续监控,定位切换瓶颈,避免“盲目优化”;
- 平衡原则:并发并非越高越好,需在“吞吐量”与“切换开销”间找到平衡,例如:线程池并非越大越好,I/O复用并非适用于所有场景。
最终,优秀的Linux服务器程序应是“低切换、高吞吐”的结合体——让CPU更多地用于业务逻辑处理,而非内核态的切换操作。








