


LightX2V模型下载与管理:从HuggingFace到本地缓存的智能方案
LightX2V模型下载与管理:从HuggingFace到本地缓存的智能方案
【免费下载链接】lightx2v  项目地址: https://gitcode.com/GitHub_Trending/li/lightx2v
项目地址: https://gitcode.com/GitHub_Trending/li/lightx2v
想要快速上手LightX2V视频生成模型,却苦于模型下载和管理?别担心,这篇完整指南将为您揭秘从HuggingFace下载到本地智能缓存的终极解决方案!🔥
LightX2V是一个强大的视频生成框架,支持多种先进模型,包括Wan2.1、Wan2.2、HunyuanVideo-1.5和Qwen-Image系列。通过智能的模型下载和缓存机制,您可以轻松管理大型模型文件,享受高效推理体验。
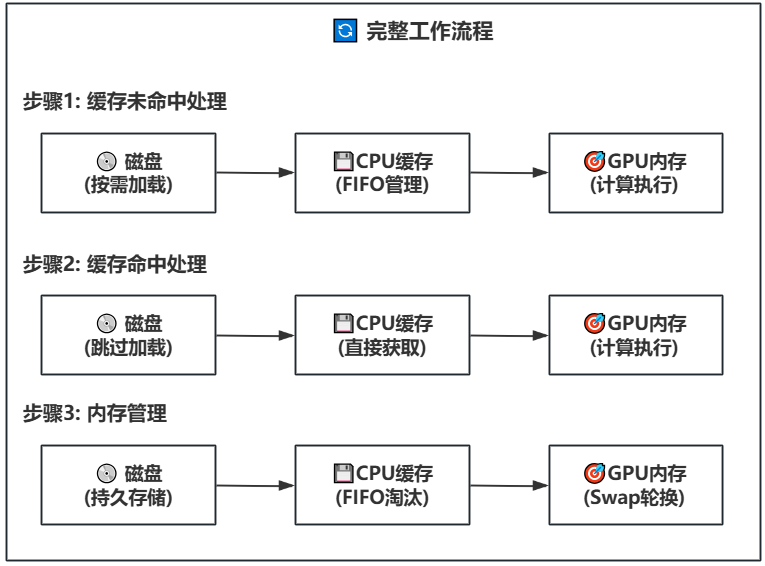
📥 模型下载全流程解析
从HuggingFace获取模型文件
LightX2V支持从多个官方HuggingFace仓库下载模型:
- HunyuanVideo-1.5:腾讯混元视频生成模型
- Wan2.1 & Wan2.2:先进的视频生成架构
- Qwen-Image系列:包括Qwen-Image-Edit-2511等图像编辑模型
智能本地缓存机制
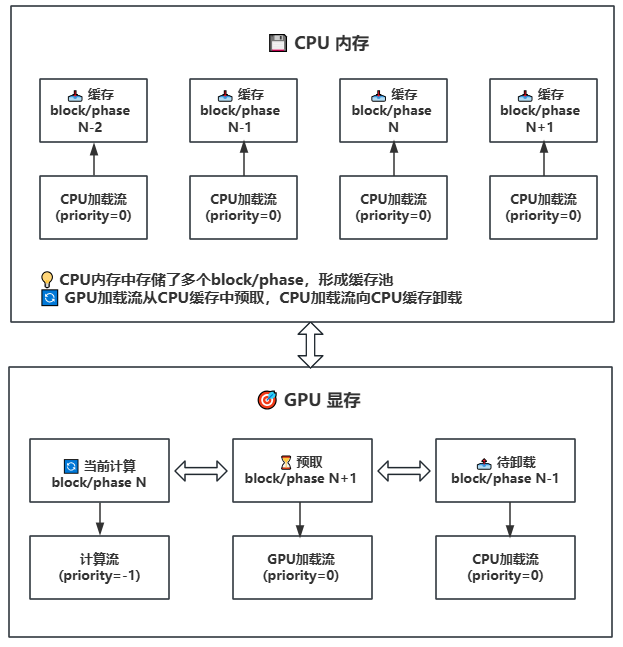
LightX2V的缓存系统采用先进的Swap技术,实现高效的模型管理:
- CPU内存缓存池:存储多个block/phase,形成智能缓存
- GPU显存预取:通过加载流从CPU缓存中预取模型块
- 动态内存管理:支持FIFO淘汰策略和持久化存储
🚀 高效模型管理策略
多级缓存配置
在配置文件中,您可以设置不同的缓存策略:
- TeaCache:基于阈值的智能缓存
- MagCache:支持校准和保留比率的高级缓存
模型路径配置
在lightx2v/pipeline.py中,通过model_path参数指定本地模型存储位置:
pipe = LightX2VPipeline(
model_path="/path/to/your/model",
model_cls="wan2.1",
task="t2v",
)
💡 最佳实践与技巧
模型存储优化
- 将模型存储在SSD磁盘上以获得更好的读取性能
- 合理配置缓存大小,避免内存溢出
- 定期清理不必要的模型文件
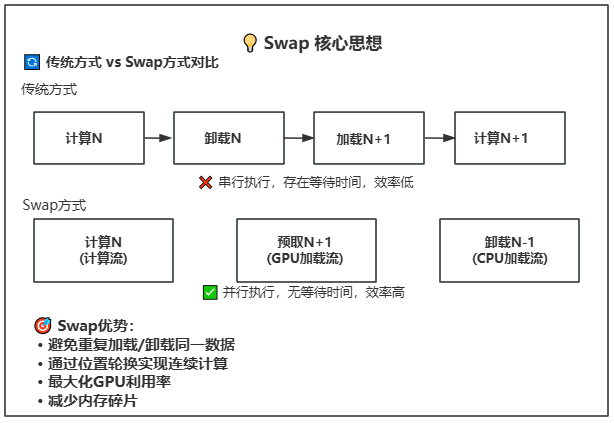
🎯 性能对比分析
LightX2V的Swap技术相比传统方式带来显著性能提升:
- 传统方式:串行执行,存在等待时间
- Swap方式:并行执行,无等待时间
量化模型支持
通过量化技术,LightX2V支持多种量化格式:
- NVFP4量化:针对RTX 40系列显卡优化
- FP8量化:平衡精度和性能的最佳选择
🔧 故障排除指南
常见问题解决
- 模型下载失败:检查网络连接和HuggingFace访问权限
- 缓存命中率低:调整缓存参数和模型预取策略
📈 持续优化建议
随着LightX2V项目的不断发展,建议:
- 关注官方HuggingFace主页获取最新模型
- 定期更新框架以享受最新的优化功能
通过这套完整的模型下载与管理方案,您可以轻松驾驭LightX2V的强大功能,享受流畅的视频生成体验!🎉
无论您是新手还是资深用户,LightX2V的智能缓存机制都能为您提供最佳的使用体验。立即开始您的视频创作之旅吧!✨
【免费下载链接】lightx2v 项目地址: https://gitcode.com/GitHub_Trending/li/lightx2v
本文地址:https://www.yitenyun.com/4745.html
上一篇:什么是右值引用







