


小白从零开始勇闯人工智能:计算机视觉初级篇(OpenCV进阶操作(下))
引言
在掌握基础图像操作后,接下来我们将进阶至对视频动态内容分析与内容生成。本文将介绍“背景建模”、“光流估计”、“物体跟踪”、“风格迁移”及“视频风格迁移”五个部分,深入了解OpenCV中对应的高级模块。
一、背景建模:动态场景中的运动目标提取
1、技术原理
背景建模的核心是通过分析视频序列建立背景的统计模型,从而分离出显著偏离该模型的运动前景。混合高斯模型(MOG2)作为经典方法,为每个像素使用多个高斯分布来模拟其随时间变化的颜色值,从而能够有效处理光照缓慢变化、背景细微摆动等动态场景,具备较强的适应性。
2、代码详解
1.首先我们导入我们所需要的库同时使用cv2.VideoCapture对象打开名为test.avi的视频文件,准备进行逐帧读取:
import cv2
cap = cv2.VideoCapture('test.avi')
2.使用OpenCV的cv2.getStructuringElement函数创建一个3x3的十字形结构元素,作为形态学操作的卷积核。十字形核能有效保留角点与线条特征,适用于后续的开运算等操作,以消除前景掩膜中的细小噪声点,平滑目标轮廓,从而提升运动检测或图像处理任务的效果。
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (3,3))
3.创建一个MOG2背景减除算法的核心处理器。它将自动处理视频序列,通过内部的高斯混合模型为每个像素点建立并实时更新背景模型。在调用其 apply 方法对每一帧进行处理时,它会计算当前帧与动态背景模型的差异,直接输出一个区分前景(运动目标)和背景的二值掩膜,是实现运动目标检测的第一步关键操作。通过调整其参数(如方差阈值),可以控制模型对光照变化和动态背景的适应速度与灵敏度。
fgbg = cv2.createBackgroundSubtractorMOG2()
4.构建实时背景建模与前景提取的核心处理循环。循环持续从视频捕获对象cap中读取每一帧图像,并将其输入预先建立的MOG2背景减法器fgbg。apply方法在每个循环中同步执行两个关键任务:一是利用当前帧动态更新内部的高斯混合背景模型,使其适应场景变化,二是基于更新后的模型,立即计算并输出一个二值化的前景掩膜fgmask,其中白色像素代表检测到的运动前景目标。
while (True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
5.使用OpenCV的形态学开运算处理前景掩膜:通过cv2.MORPH_OPEN参数,先对图像进行腐蚀操作以消除细小的前景噪点(如椒盐噪声),再执行膨胀操作以恢复主要运动目标的原有形状与轮廓。这能有效净化掩膜,在抑制噪声干扰的同时,保持真实运动区域的完整性。
fgmask_new = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
6.接着再使用cv2.findContours函数对经过开运算去噪后的前景掩膜fgmask_new进行轮廓检测。其中,参数cv2.RETR_EXTERNAL指定仅提取最外层轮廓,忽略所有内部嵌套结构,cv2.CHAIN_APPROX_SIMPLE则对轮廓进行压缩,仅保留关键端点坐标,从而高效表示轮廓形状并节省存储空间。函数最终返回一个轮廓列表,每个轮廓由一系列点构成,为后续的运动目标分析、定位与绘制打下基础。
_, contours, h = cv2.findContours(fgmask_new, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
7.最后构建一个循环对检测到的轮廓进行筛选与标注:首先计算每个轮廓的周长,并通过设定大于188的经验阈值,滤除由残留噪声或微小运动(如树叶晃动)产生的小轮廓,从而聚焦于显著的运动目标,随后获取符合条件轮廓的最小外接矩形,并在原始帧画面上以绿色线条绘制矩形框,最终实现运动目标的直观框选与可视化。
for c in contours:
perimeter = cv2.arcLength(c, True)
if perimeter > 188:
x, y, w, h = cv2.boundingRect(c)
fgmask_new_rect = cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
8.运行结果
cv2.imshow('fgmask_new_rect', fgmask_new_rect)
k = cv2.waitKey(60)
if k == 27:
break

二、光流估计:追踪像素级运动轨迹
1、技术原理
光流描述了图像中像素点在连续帧间的运动矢量。Lucas-Kanade算法是一种基于局部邻域光流一致的稀疏光流法。它假设一个像素点在小时间间隔内,其邻域内所有像素点的运动方向一致,并通过最小二乘法求解该点的运动速度矢量。结合图像金字塔,可以处理更大的像素位移。
2、代码详解
1.导入库并打开视频
import numpy as np
import cv2
cap = cv2.VideoCapture('test.avi')
2.接着随机生成100种颜色,用于区分不同特征点的运动轨迹
color = np.random.randint(0, 255, (100, 3))
3.通过cap.read()捕获视频序列的第一帧作为参考帧old_frame,随后使用cv2.cvtColor将其从BGR色彩空间转换为灰度图像old_gray。这一转换至关重要,因为后续的光流计算依赖连续帧间的灰度强度变化进行分析,在单通道的灰度空间中进行运算,能显著减少数据维度,为高效的运动追踪打下基础。
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
4.接着初始化特征点:通过cv2.goodFeaturesToTrack函数,基于Shi-Tomasi角点检测算法在首帧灰度图old_gray中提取关键点。参数设置平衡了效率与效果:最多检测100个角点(maxCorners),以最佳响应值的30%作为质量阈值(qualityLevel)筛选显著点,并保证角点间至少7像素距离(minDistance)以避免聚集。输出的p0是一个包含N个角点坐标的数组。
feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
5.初始化光流追踪所需的两个关键组件:首先,mask被创建为一个与第一帧尺寸相同的全黑图像,它将用于后续动态绘制特征点的运动轨迹,从而可视化光流路径,其次,lk_params字典定义了Lucas-Kanade光流算法的核心参数,其中winSize设定了用于计算每个点光流的局部窗口尺寸,而maxLevel则指定了图像金字塔的层数。
mask = np.zeros_like(old_frame)
lk_params = dict(winSize=(15, 15), maxLevel=2)
6.构建光流追踪的核心循环:在视频序列中持续读取新帧并转换为灰度图像后,调用cv2.calcOpticalFlowPyrLK函数基于前一帧的灰度图像old_gray及其特征点p0,计算其在当前帧灰度图像frame_gray中的新位置p1。该函数同时返回状态向量st(指示每个特征点是否被成功跟踪)和误差向量err(反映跟踪的置信度),从而实现对运动特征的连续、动态追踪。
while True:
ret, frame = cap.read()
if not ret: break
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
7.筛选有效点:根据状态st,只保留成功跟踪到的特征点在新旧帧中的位置。
good_new = p1[st == 1]
good_old = p0[st == 1]
8.光流追踪结果的可视化:遍历所有成功跟踪的特征点对,获取它们在当前帧与前一帧中的整数坐标,并在专用的轨迹图层 mask 上绘制出从旧位置指向新位置的彩色线段,从而动态累积出每条轨迹的运动路径。最后,通过 cv2.add 将轨迹图层与当前视频帧叠加,生成直观显示运动矢量与目标移动趋势的最终图像 img,实现了对光流信息的清晰、实时视觉反馈。
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
a, b, c, d = int(a), int(b), int(c), int(d)
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
img = cv2.add(frame, mask)
9.显示结果图像。
cv2.imshow('frame', img)
# 等待150ms,检测是否按下了Esc键(键码为27)
k = cv2.waitKey(150)
if k == 27: # 按下Esc键,退出循环
break
10.状态更新:将当前帧灰度图作为下一循环的“旧帧”,并将当前帧成功跟踪到的点good_new重塑为(N,1,2)格式,作为下一循环的“旧特征点”p0。
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
11.运行结果
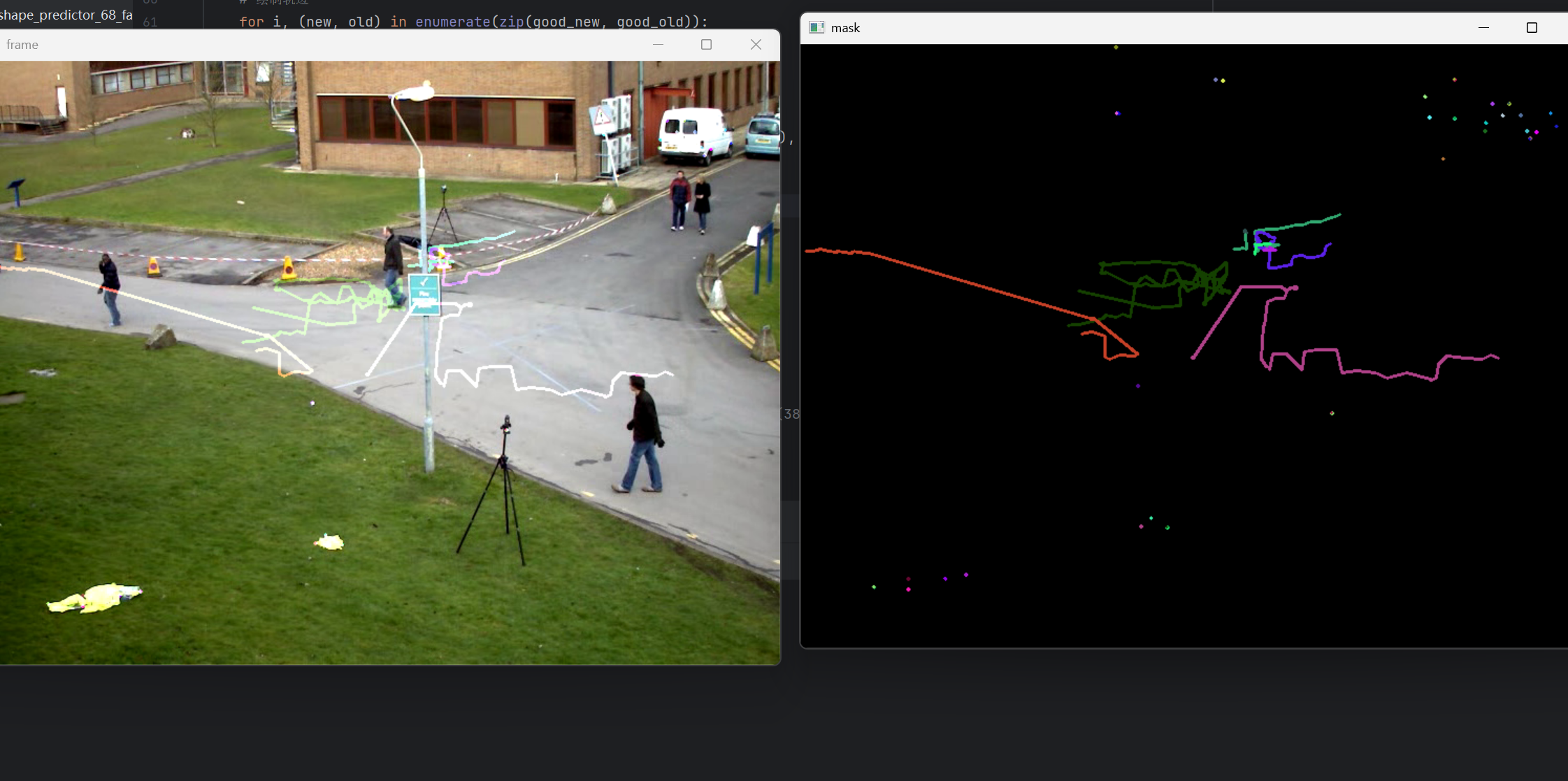
三、物体跟踪:基于检测的持续目标锁定
1、技术原理
物体跟踪的核心是在视频序列中持续定位特定目标。OpenCV中的CSRT(Channel and Spatial Reliability Tracker)算法可以通过融合空间可靠性与通道可靠性来构建目标模型:空间可靠性关注目标区域的形状与位置稳定性,通道可靠性则综合评估颜色、梯度等多通道信息的重要程度,以增强特征判别力。基于判别式相关滤波的定位机制,该算法能够有效应对目标形变、旋转及部分遮挡,从而在复杂场景中保持稳定的跟踪性能。
2、代码详解
1.初始化:创建CSRT跟踪器实例,其中,tracking标志初始化为False,表示尚未开始跟踪,接着打开默认摄像头(索引0)准备捕获实时视频流。
import cv2
tracker = cv2.TrackerCSRT_create()
tracking = False
cap = cv2.VideoCapture(0)
2.实现跟踪器的手动初始化:在视频流循环中,程序持续读取帧并检测按键,当按下's'键时,系统进入跟踪准备状态,调用cv2.selectROI弹出交互窗口,可以通过鼠标直接在当前帧上框选目标区域作为初始ROI。随后,该帧与选定的ROI被传递给跟踪器的init方法,使跟踪器学习目标的特征模型。
while True:
ret, frame = cap.read()
if not ret: break
if cv2.waitKey(1) == ord('s'):
tracking = True
roi = cv2.selectROI('Tracking', frame, showCrosshair=False)
tracker.init(frame, roi)
3.当跟踪被激活后,对每一帧调用 tracker.update() 方法,基于已学习的模型预测目标的新位置。若跟踪成功(success 为 True),该方法会返回一个包含目标当前位置的边界框 box,代码随后将该浮点数坐标转换为整型,并在当前视频帧上绘制一个绿色的矩形框来直观地标定被跟踪目标,从而提供实时的视觉反馈。
if tracking:
success, box = tracker.update(frame)
if success:
x, y, w, h = [int(v) for v in box]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
4.运行结果
cv2.imshow('Tracking', frame)
# 检查是否按下了ESC键(ASCII码27),如果按下则退出循环
if cv2.waitKey(1) == 27:
break


四、风格迁移:将艺术风格应用于图像
1、技术原理
神经风格迁移是一种基于深度学习的图像处理技术,它通常利用预训练的卷积神经网络(如VGG)来分解和重组图像的内容与风格。该技术的核心在于设计一个多部分的损失函数,分别衡量生成图像与内容原图在高级语义特征上的差异,以及与风格参考图(如艺术作品)在纹理、色彩分布等统计特征上的差异。通过梯度下降方法迭代优化生成图像的像素值,使其在保留内容图像基本结构和对象的同时,融合风格图像的艺术笔触与视觉美感,从而创造出兼具两者特点的全新图像。
2、代码详解
1.加载输入图像:读取内容图像car.png,并获取其高度h和宽度w
import cv2
image = cv2.imread('R-C.png')
(h, w) = image.shape[:2]
2.用OpenCV的DNN模块对输入图像进行预处理,将其转换为神经网络模型所需的规范输入格式。cv2.dnn.blobFromImage 函数接收原始图像,并根据指定参数执行标准化操作:保持像素值原始比例(缩放因子为1),维持图像原始尺寸(w, h),不进行均值减法,并保留BGR通道顺序(不交换红蓝通道)。最终生成的blob是一个四维张量(批大小、通道数、高度、宽度),可直接作为前向传播的输入,确保了数据格式与模型训练时的一致性。
blob = cv2.dnn.blobFromImage(image, 1, (w, h), (0, 0, 0), swapRB=False, crop=False)
3.加载预训练模型:cv2.dnn.readNet():从文件加载训练好的神经网络模型,starry_night.t7:一个以Torch格式保存的、已学习梵高《星夜》风格的特征变换网络模型。
net = cv2.dnn.readNet(r'modelstarry_night.t7')
4.网络推理过程:首先通过net.setInput()将预处理后的blob数据(符合网络输入要求的四维张量)馈入已加载的模型,随后调用net.forward()执行网络的前向传播计算,触发各层对输入数据的特征提取与变换,最终生成并返回输出张量out。该输出通常为包含预测结果(如分类概率、检测框或风格特征)的四维数据结构(1, C, H, W),为后续的任务提供可直接处理的数据基础。
net.setInput(blob)
out = net.forward()
5.对神经网络的输出张量进行关键的后处理操作:首先通过reshape移除批处理维度,将四维输出转换为三维结构(通道、高度、宽度),随后利用cv2.normalize对数据进行归一化,将数值线性缩放到标准范围(如0到1),确保图像数据能够正常显示,最后通过transpose调整维度顺序,转换为OpenCV图像格式(高度、宽度、通道),从而得到可直接可视化或保存的最终结果图像。
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
result = out_new.transpose(1, 2, 0)
6.运行结果
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()

五、视频风格迁移:实时艺术化渲染
1、技术原理
将图像风格迁移技术扩展到视频流。核心是对视频的每一帧独立地应用风格迁移网络。为了保证视频的时间连贯性(避免帧间闪烁),可能需要更复杂的处理,但本基础实现采用了逐帧独立处理的方式。
2、代码详解
1.初始化:打开视频文件并加载相同的风格迁移模型。也可将参数cxk.mp4改为0以使用摄像头实时输入。
import cv2
cap = cv2.VideoCapture('text.avi')
net=cv2.dnn.readNetFromTorch(r'.modelstarry_night.t7')
2.逐帧处理循环:读取视频帧。关键不同点:swapRB=True。这里将红蓝通道交换,因为许多公开的预训练风格迁移模型是在RGB图像上训练的,而OpenCV读取的frame是BGR格式。swapRB=True能将其转换为RGB。
while True:
ret, frame = cap.read()
if not ret: break
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1, (w, h), (0, 0, 0), swapRB=True, crop=False)
3.后面部分的处理流程与图像风格迁移完全相同。对每一帧进行网络推理、后处理,并实时显示风格化后的结果。
net.setInput(blob)
out = net.forward()
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
result = out_new.transpose(1, 2, 0)
cv2.imshow('result', result)
4.运行结果
cv2.imshow('result', result)
key_pressed = cv2.waitKey(10) #60
if key_pressed == 27: # 如果按下esc键,就退出循环
break







