使用SSH连接远程PyTorch服务器:安全高效的开发方式
使用SSH连接远程PyTorch服务器:安全高效的开发方式
在深度学习项目日益复杂的今天,许多开发者都曾面临这样的窘境:本地笔记本上的RTX 3060跑不动大模型,训练一个epoch要两小时,还动不动显存溢出。而与此同时,数据中心里成排的A100正空闲着算力。如何把代码“扔”到那些高性能GPU上运行?答案就是——通过SSH连接远程PyTorch服务器。
这不仅是简单的“换台电脑跑程序”,而是一套完整的现代AI开发范式。它融合了容器化环境、加密通信、分布式计算等多个关键技术点,背后体现的是从“个人工作站”向“云端协作平台”的演进趋势。
PyTorch-CUDA 镜像:让GPU开箱即用
我们先来看最核心的一环:为什么非得用PyTorch-CUDA镜像?
很多人第一次尝试在服务器上装PyTorch时,往往会被CUDA驱动、cuDNN版本、Python依赖之间的复杂关系搞得焦头烂额。明明pip install成功了,但torch.cuda.is_available()却返回False——这种“在我机器上能跑”的问题,在团队协作中尤为致命。
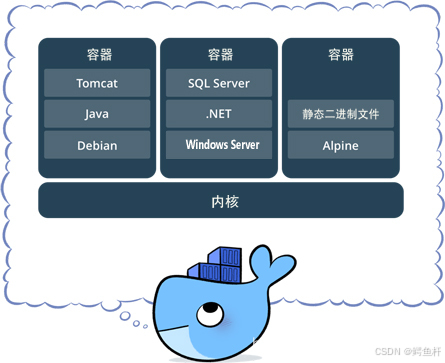
而PyTorch-CUDA镜像的价值,正在于把整个软件栈固化下来。以常见的PyTorch-CUDA-v2.9为例,它本质上是一个预配置好的Linux系统快照,里面已经集成了:
- 匹配的NVIDIA驱动 + CUDA 12.x
- cuDNN 8.9优化库
- PyTorch 2.9(带CUDA支持)
- 常用科学计算包(NumPy, Pandas, Matplotlib等)
- Jupyter Lab / TensorBoard等辅助工具
这意味着你不再需要手动处理任何版本兼容性问题。只要服务器有NVIDIA GPU,拉取镜像后几乎可以立即开始训练。
更进一步地,这类镜像通常基于Docker或虚拟机模板构建,支持一键部署。比如在云平台上选择“PyTorch Deep Learning AMI”,几分钟内就能获得一个 ready-to-go 的GPU实例。
实际怎么用?
假设你已经有了这样一个环境,第一步永远是验证GPU是否正常工作:
import torch
if torch.cuda.is_available():
device = torch.device('cuda')
print(f"✅ 使用GPU: {torch.cuda.get_device_name(0)}")
print(f" 显存总量: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
else:
device = torch.device('cpu')
print("⚠️ 未检测到可用GPU,请检查CUDA安装")
一旦确认环境无误,后续所有张量操作都可以通过.to(device)自动迁移到GPU:
# 模型和数据都放到GPU上
model = MyNeuralNet().to(device)
data = torch.randn(64, 3, 224, 224).to(device)
output = model(data) # 计算将在GPU执行
你会发现,原本需要数小时的任务现在可能只要几十分钟完成。这不是魔法,而是正确的工具链带来的效率跃迁。
SSH:不只是远程登录,更是生产力管道
有了强大的远程环境,下一步是如何安全高效地与之交互。这时候很多人会想到VNC或者RDP这类图形化远程桌面方案。但真正在一线工作的工程师,绝大多数时间都在敲SSH命令。
为什么?
因为SSH不是“看”远程桌面,而是“融入”远程系统。它像一根轻量级的数据管道,把你本地的终端、脚本、文件管理能力无缝延伸到千里之外的服务器。
安全性是底线
SSH的核心价值首先是安全。它使用公钥加密机制建立端到端加密通道,默认端口22上的所有流量都会被AES等强算法保护。即使网络被监听,攻击者也无法获取你的密码或代码内容。
实际使用中最推荐的做法是配置免密登录:
# 本地生成密钥对
ssh-keygen -t ed25519 -C "yourname@company.com"
# 把公钥传到服务器
ssh-copy-id user@192.168.1.100
此后每次连接都不再需要输入密码,既提升了效率,又避免了明文密码传输的风险。更重要的是,你可以结合~/.ssh/config文件做别名管理:
Host gpu01
HostName 192.168.1.100
User ml-engineer
IdentityFile ~/.ssh/id_ed25519_gpu
Port 2222
之后只需一句ssh gpu01即可快速接入,适合多服务器管理场景。
自动化才是王道
SSH的强大之处在于它可以轻松集成进自动化流程。例如:
# 查看GPU状态
ssh gpu01 nvidia-smi
# 启动后台训练任务
ssh gpu01 "nohup python train.py --epochs 100 > train.log &"
# 同步最新代码
rsync -avz ./src/ gpu01:~/project/src/
# 下载训练好的模型
scp gpu01:~/checkpoints/best_model.pth ./
这些命令完全可以写成shell脚本,实现一键提交、监控、拉取结果的闭环。相比之下,图形界面方案很难做到这种级别的自动化控制。
如果你需要长期运行任务,建议搭配tmux或screen使用:
# 创建一个持久会话
ssh gpu01
tmux new -s training
# 在会话中启动训练
python train.py
# 断开连接(任务仍在后台运行)
Ctrl+B, 然后按 D
# 稍后重新连接查看进度
ssh gpu01
tmux attach -t training
这样即使本地网络中断,训练也不会终止。
典型工作流:从写代码到拿结果
让我们还原一个真实的研究员日常:
早上9点,你在咖啡馆打开笔记本,准备继续昨天没跑完的实验。你不需要开机等待Windows启动,也不用担心电量不足——因为你所有的重型计算都在远程进行。
第一步,建立连接:
ssh gpu01
第二步,进入项目目录并查看任务状态:
cd ~/projects/vision-transformer
nvidia-smi # 看GPU占用
tail -f train.log # 查看日志输出
发现上次训练已结束,但准确率不够理想。于是你决定调整学习率重新试一次。
第三步,修改本地代码并上传:
# 在本地编辑器改好train.py后同步
rsync -avz train.py gpu01:~/projects/vision-transformer/
第四步,启动新任务:
ssh gpu01
cd ~/projects/vision-transformer
tmux new -s exp_v2
python train.py --lr 1e-4
第五步,断开连接,去做别的事。晚上回家后再连上去看结果:
ssh gpu01
tmux attach -t exp_v2
# 或直接分析指标
python eval.py --ckpt checkpoints/latest.pth
整个过程无需图形界面,完全由文本指令驱动,却异常高效。这就是为什么很多资深AI工程师坚持“Terminal Only”工作模式的原因。
工程实践中的关键考量
当然,这套方案也不是毫无门槛。要想真正发挥其优势,还需要注意一些工程细节。
安全加固不可忽视
虽然SSH本身很安全,但公网暴露的服务器仍是攻击目标。几点建议:
- 禁用root登录:在
/etc/ssh/sshd_config中设置PermitRootLogin no - 更换默认端口:将SSH从22改为非常见端口(如2222),减少机器人扫描
- 限制IP访问:通过防火墙只允许公司或家庭IP连接
- 启用Fail2Ban:自动封禁多次尝试失败的IP地址
性能优化要点
为了让GPU充分运转,还需合理配置训练参数:
# DataLoader中适当增加worker数量
dataloader = DataLoader(
dataset,
batch_size=64,
num_workers=8, # 根据CPU核心数调整
pin_memory=True # 加速GPU内存拷贝
)
# 避免CPU-GPU瓶颈
for data, label in dataloader:
data = data.to(device, non_blocking=True)
label = label.to(device, non_blocking=True)
同时建议使用SSD存储数据集,否则HDD的IO延迟会严重拖慢整体速度。
成本控制策略
对于使用云服务的情况,成本是绕不开的话题。几个实用技巧:
- 按需启停:训练时不关机,空闲时立即关闭实例
- 使用竞价实例(Spot Instance):价格可低至按需实例的1/5,适合容错性强的任务
- 镜像快照复用:做好一次环境后保存为自定义镜像,下次快速重建
写代码在笔记本,跑训练在云端
回到最初的问题:我们为什么需要SSH连接远程PyTorch服务器?
答案其实很简单:让每台设备做它最擅长的事。
你的MacBook Air不适合跑ResNet-50,但它非常适合用来写代码、画图、读论文;
数据中心里的A100不应该闲置,但它也不该被人天天去机房插键盘操作。
SSH + PyTorch-CUDA镜像的组合,正是打通这两端的桥梁。它不仅解决了算力瓶颈,更重要的是建立起一种标准化、可复制、易协作的开发模式。
无论是高校实验室共享一台GPU服务器,还是创业团队共用云资源,这套方法都能显著降低协作成本。每个人都有自己的SSH账户,既能独立工作,又能共享数据和模型,权限清晰,操作透明。
未来,随着MLOps理念的普及,这种“轻本地、重远程”的架构还会进一步演化。也许有一天,我们会像使用水电一样使用AI算力——不用关心底层硬件,只需专注模型创新。而今天你掌握的每一个ssh和scp命令,都是通往那个未来的垫脚石。