斯坦福大学 | CS336 | 从零开始构建语言模型 | Spring 2025 | 笔记 | Assignment 1: Experiments Implement
目录
- 前言
- 1. Problem (experiment_log): Experiment logging (3 points)
- 2. Problem (learning_rate): Tune the learning rate (3 points) (4 H100 hrs)
- 3. Problem (batch_size_experiment): Batch size variations (1 point) (2 H100 hrs)
- 4. Problem (generate): Generate text (1 point)
- 5. Problem (layer_norm_ablation): Remove RMSNorm and train (1 point) (1 H100 hr)
- 6. Problem (pre_norm_ablation): Implement post-norm and train (1 point) (1 H100 hr)
- 7. Problem (no_pos_emb): Implement NoPE (1 point) (1 H100 hr)
- 8. Problem (swiglu_ablation): SwiGLU vs. SiLU (1 point) (1 H100 hr)
- 8. Problem (main_experiment): Experiment on OWT (2 points) (3 H100 hrs)
- 9. Problem (leaderboard): Leaderboard (6 points) (10 H100 hrs)
- 结语
- 源码下载链接
- 参考
前言
在上篇文章 斯坦福大学 | CS336 | 从零开始构建语言模型 | Spring 2025 | 笔记 | Assignment 1: Experiments 中,我们已经了解了 Experiments 的作业要求,下面我们就一起来看看这些作业该如何实现,本篇文章记录 CS336 作业 Assignment 1: Basics 中的 Experiments 实现,仅供自己参考😄
Note:博主并未遵循 from-scratch 的宗旨,所有代码几乎均由 ChatGPT 完成
Assignment 1:https://github.com/stanford-cs336/assignment1-basics
reference:https://chatgpt.com/
reference:https://github.com/donglinkang2021/cs336-assignment1-basics
reference:https://github.com/Louisym/Stanford-CS336-spring25
1. Problem (experiment_log): Experiment logging (3 points)
请为你的训练与评估代码构建一套 实验跟踪(experiment tracking)基础设施,使你能够根据 梯度更新步数(gradients)和实际耗时(wall-clock)time 来追踪实验过程及对应的损失曲线。
Deliverable:用于实验的日志记录/追踪基础设施代码,一份实验日志文档记录你在本节后续各个作业问题中尝试过的所有实验设置与结果。
experiment_tracking 代码如下:
import os
import json
import time
from dataclasses import asdict, is_dataclass
from typing import Any, Optional
class ExperimentTracker:
"""
A lightweight experiment tracker that logs scalar metrics against:
- global step (gradient update count)
- wall-clock time (seconds since run start)
Logs are written to:
runs//metrics.jsonl
runs//config.json
"""
def __init__(
self,
run_dir: str,
config: Any,
*,
use_wandb: bool = False,
wandb_project: str = "cs336-a1",
wandb_run_name: Optional[str] = None
) -> None:
self.run_dir = run_dir
os.makedirs(self.run_dir, exist_ok=True)
self.metrics_path = os.path.join(self.run_dir, "metrics.jsonl")
self.config_path = os.path.join(self.run_dir, "config.json")
self.t0 = time.time()
# Write config once for reproducibility
cfg_obj = self._to_jsonable(config)
with open(self.config_path, "w", encoding="utf-8") as f:
json.dump(cfg_obj, f, indent=2, sort_keys=True)
self._wandb = None
self._wandb_enabled = use_wandb
if use_wandb:
import wandb
self._wandb = wandb
self._wandb.init(
project=wandb_project,
name=wandb_run_name,
config=cfg_obj,
dir=self.run_dir
)
def wall_time_s(self) -> float:
return time.time() - self.t0
def log(self, step: int, metrics: dict[str, float | int]) -> None:
"""
Log a dictionary of scalar metrics at a given step.
A wall_time_s field will be automatically added.
"""
record = {"step": int(step), "wall_time_s": float(self.wall_time_s())}
for k, v in metrics.items():
record[k] = float(v) if isinstance(v, (int, float)) else v
# Append to JSONL
with open(self.metrics_path, "a", encoding="utf-8") as f:
f.write(json.dumps(record) + "
")
# Optional wandb
if self._wandb_enabled and self._wandb is not None:
self._wandb.log(record, step=int(step))
def close(self) -> None:
if self._wandb_enabled and self._wandb is not None:
self._wandb.finish()
@staticmethod
def _to_jsonable(obj: Any) -> Any:
if is_dataclass(obj):
return asdict(obj)
if isinstance(obj, dict):
return {k: ExperimentTracker._to_jsonable(v) for k, v in obj.items()}
if isinstance(obj, (list, tuple)):
return [ExperimentTracker._to_jsonable(x) for x in obj]
# Basic types
if obj is None or isinstance(obj, (str, int, float, bool)):
return obj
# Fallback
return str(obj)
上面实现的代码用 config.json + metrics.jsonl(step + wall_time) 建立了一个不依赖外部服务也能复现实验的最小实验追踪系统,并可选同步到 wandb,其中:
config.json:只写一次(初始化时写入),内容其实就是配置文件 config.py 被转换成 JSON 的格式,这个文件方便我们复现实验,其保存的文件示例如下:
{
"data": {
"context_length": 256,
"device": "cuda:0",
"np_dtype": "uint16",
"train_data_path": "workspace/tinystories_train.uint16.bin",
"val_data_path": "workspace/tinystories_valid.uint16.bin"
},
"model": {
"context_length": 256,
"d_ff": 1344,
"d_model": 512,
"max_seq_len": null,
"num_heads": 16,
"num_layers": 4,
"rmsnorm_eps": 1e-05,
"rope_theta": 10000.0,
"torch_dtype": "float32",
"vocab_size": 10000
},
"optim": {
"beta1": 0.9,
"beta2": 0.999,
"cosine_cycle_iters": 106667,
"eps": 1e-08,
"grad_clip": 1.0,
"lr_max": 0.001,
"lr_min": 0.0001,
"warmup_iters": 2000,
"weight_decay": 0.1
},
"run": {
"run_name": null,
"run_name_prefix": "ts_baseline",
"runs_dir": "runs"
},
"train": {
"batch_size": 12,
"ckpt_interval": 5000,
"eval_batches": 20,
"eval_interval": 2000,
"log_interval": 50,
"max_steps": 106667,
"resume_from": null,
"seed": 42
},
"wandb": {
"enable": true,
"project": "cs336-a1",
"run_name": "train"
}
}
metrics.jsonl:逐条 append,内容是每次训练一定轮次时记录的日志信息,包括 wall_time_s、train loss 等等信息,其保存的文件示例如下:
{"step": 50, "wall_time_s": 9.37568712234497, "train/loss": 8.581323623657227, "train/lr": 2.4500000000000003e-05, "train/tok_s": 24571.608597325194}
{"step": 100, "wall_time_s": 15.304110765457153, "train/loss": 7.062735557556152, "train/lr": 4.9500000000000004e-05, "train/tok_s": 25909.52138827671}
{"step": 150, "wall_time_s": 21.231520652770996, "train/loss": 5.746219635009766, "train/lr": 7.45e-05, "train/tok_s": 25913.32107691957}
代码实现比较简单,大家可以自己看看
2. Problem (learning_rate): Tune the learning rate (3 points) (4 H100 hrs)
学习率是最重要、也最需要精细调节的超参数之一,基于你已经训练好的基础模型,请回答以下问题:
(a)对学习率进行一次超参数扫描(hyperparameter sweep),并汇报最终的损失值(如果优化器发散,则注明发生了发散)
Deliverable:不同学习率对应的学习曲线;对你的超参数搜索策略进行说明。
Deliverable:在 TinyStories 数据集上,验证集的逐 token 损失不高于 1.45 的模型。
本次超参数扫描的实验设置如下:
- 数据集:TinyStories
- 模型:TransformerLM(d_model=512, num_layers=4, num_heads=16, d_ff=1344, context_length=256)
- 优化器:AdamW(beta1=0.9, beta2=0.999, weight_decay=0.1, grad_clip=1.0)
- 学习率调度:warmup + cosine decay(warmup_iters=100)
- 评估指标:validation per-token loss(同时记录 ppl)
超参数扫描策略(两阶段:粗扫→精扫)
为了在有限算力下尽快定位有效区间,博主采用了 “两阶段” 策略:
Note:博主实验设备是 8GB 显存的 RTX4060,在上面的模型参数配置下,在 GPU 上训练可运行的最大 batch 数是 12,大家务必根据自身的硬件资源条件来调整相关参数配置进行相关实验
1)粗粒度 sweep:对数量级做扫描
先在较短训练步数(max_steps=3000)下做对数量级扫描,覆盖如下学习率:
[1e-4, 2e-4, 3e-4, 5e-4, 8e-4, 1e-3, 2e-3, 3e-3, 5e-3, 8e-3, 1e-2]
学习率扫描脚本代码如下:
import gc
import time
import torch
from typing import Sequence
import cs336_basics.config as config_mod
import cs336_basics.train as train_mod
def run_one(lr_max: float, *, lr_min_ratio: float = 0.1, tag: str = "") -> None:
"""
Run one training job by patching train.get_default_config() to return a modified config.
"""
cfg = config_mod.get_default_config()
# ---- override what you need for sweep ----
cfg.optim.lr_max = float(lr_max)
cfg.optim.lr_min = float(lr_max * lr_min_ratio) # IMPORTANT: set explicitly (don't rely on dataclass default)
lr_tag = "lr" + f"{lr_max:.4g}".replace(".", "p").replace("-", "m")
cfg.run.run_name = f"{lr_tag}{('_' + tag) if tag else ''}"
# cfg.wandb.enable = False
# ---- patch train_mod.get_default_config ----
def _patched_get_default_config():
return cfg
train_mod.get_default_config = _patched_get_default_config
print("
" + "=" * 80)
print(f"[SWEEP] start run: lr_max={cfg.optim.lr_max} lr_min={cfg.optim.lr_min} run_name={cfg.run.run_name}")
print("=" * 80)
# run training
train_mod.main()
# cleanup to reduce GPU memory fragmentation across runs
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def main(lrs: Sequence[float]) -> None:
t0 = time.time()
for lr in lrs:
run_one(lr, lr_min_ratio=0.1)
dt = time.time() - t0
print(f"
[SWEEP] all done. total wall time: {dt/60:.1f} min")
if __name__ == "__main__":
# coarse search
# lrs = [1e-4, 2e-4, 3e-4, 5e-4, 8e-4, 1e-3, 2e-3, 3e-3, 5e-3, 8e-3, 1e-2]
# refinement
lrs = [5e-4, 8e-4, 1.0e-3, 1.2e-3, 1.5e-3, 1.8e-3, 2.0e-3, 2.2e-3]
main(lrs)
Note:注意这里调整的学习率指的是 lr_max,而关于 lr_min 取的是 0.1 倍的 lr_max
执行 uv run scripts/sweep_lr.py 指令后输出如下图所示:
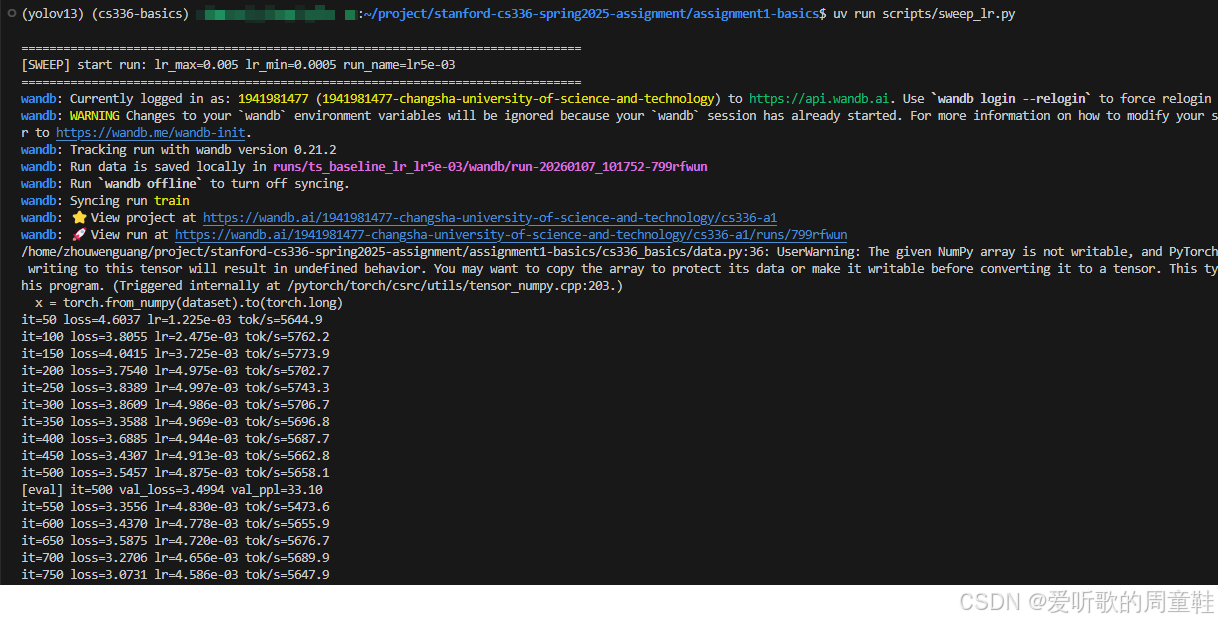
我们可以把不同学习率训练下的损失曲线绘制在一起,如下图所示:
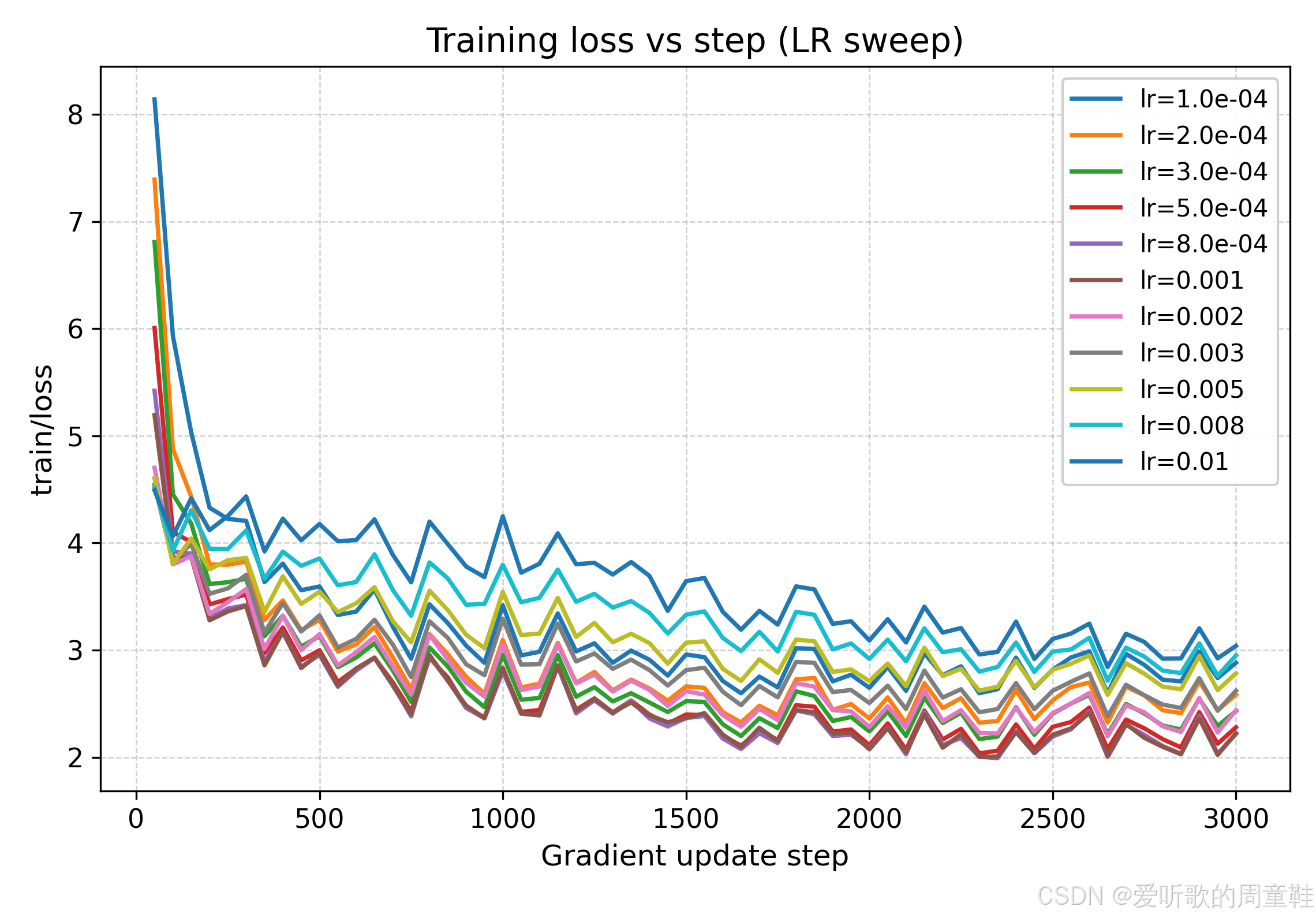

观察上图的训练/验证曲线后我们可以得到两个清晰现象:
- 过小 LR(≤ 3e-4)收敛慢:同样 step 下 val loss 明显更高(曲线整体在上方)
- 过大 LR(≥ 3e-3)并没有带来更快的有效收敛:训练 loss 波动更大、val loss 更高
从粗扫结果来看,最优学习率区域明显集中在 5e-4 ~ 2e-3 附近,val loss 曲线整体最低,且下降最快
2)精细化 sweep:围绕最优区间加密
在粗扫定位到有效区间后,博主进一步在 5e-4 ~ 2e-3 内加密测试,覆盖如下学习率:
[5e-4, 8e-4, 1.0e-3, 1.2e-3, 1.5e-3, 1.8e-3, 2.0e-3, 2.2e-3]
在这一组学习率测试下的损失曲线如下图所示:

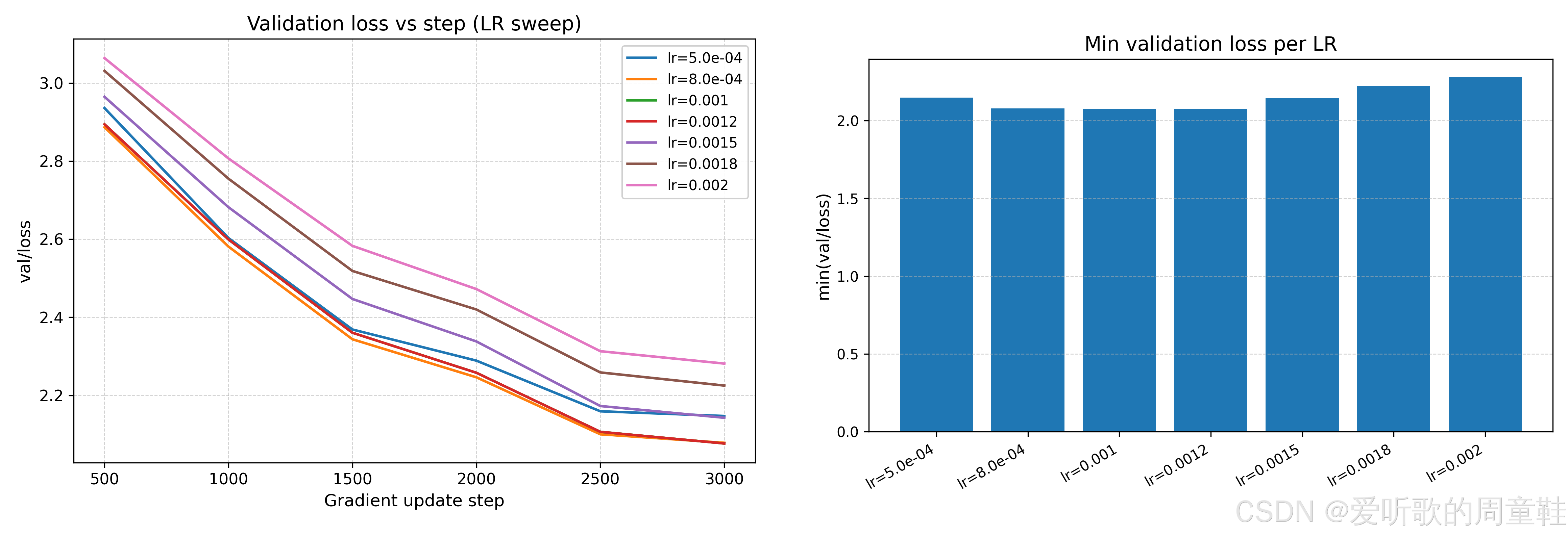
从上图结果中可以看到,当学习率在 8e-4 或 1e-3 左右整体最优、最稳,验证曲线下降快且后期保持更低,当 LR 提升到 ≥ 1.8e-3 时,验证集曲线整体开始太高,泛化变差
在完成上面的 LR 搜索后,博主最终选择 lr_max = 1e-3 作为长跑训练的学习率上界,并按作业要求对比总 token 预算,博主最终训练设置为 batch_size=12, context_length=256, max_steps=106,667,总 tokens 为:
12 × 106,667 × 256 = 1,280,004 × 256 = 327,681,024 12 imes 106{,}667 imes 256= 1{,}280{,}004 imes 256= 327{,}681{,}024 12×106,667×256=1,280,004×256=327,681,024
与作业要求的 327,680,000 基本一致
训练损失曲线如下图所示:

从上图可以看到,验证损失随训练持续下降,最终记录的最低损失值为 1.344,训练损失同步下降且较稳定,没有出现明显震荡失控
Note:验证损失的计算是从验证集中随机抽取 eval_batches=20 个小批量样本计算的,并没有对整个验证集进行完整遍历
(b)一个经验性的结论是:最优学习率通常位于 “稳定性边缘(edge of stability)”,请研究学习率开始发散的点,与最佳学习率之间的关系。
Deliverable:一组随着学习率逐渐增大的学习曲线,其中至少包含一次发散的训练运行;对这些曲线的分析,并说明学习率发散点与收敛速度之间的关系。
为了研究学习率发散点与最优学习率之间的关系,我们可以在保持模型结构、batch size 和训练步数固定的情况下,对学习率进行逐步增大的扫描,测试范围覆盖从稳定收敛到明显不稳定的区域:
lrs = [1e-3, 4e-3, 8e-3, 1.6e-2, 3.2e-2, 6.4e-2, 1e-1]
Note:博主本次实验的配置是 batch_size=12, warmup_iters=500, max_steps=10,000
不同学习率下的损失曲线如下图所示:

从图中可以看出,当学习率较小时(lr≤1.6e-2),训练和验证损失均呈现稳定、单调下降趋势,模型能够正常收敛。随着学习率进一步增大(lr≥3.2e-2),训练过程出现剧烈不稳定现象:训练损失出现大幅尖峰,验证损失显著高于低学习率设置,模型甚至难以有效收敛,这些现象表明,学习率已经超过优化器和模型所能稳定承受的范围,进入发散或准发散状态
综合来看,最优学习率(lr≈1e-3)位于模型仍能稳定训练、但已接近不稳定区域的边缘位置
3. Problem (batch_size_experiment): Batch size variations (1 point) (2 H100 hrs)
现在让我们改变 batch size(批大小),看看训练过程会发生什么变化,批大小非常重要,它可以通过执行更大的矩阵乘法来提高 GPU 的利用效率,但我们是否总是希望批大小越大越好呢?让我们通过一些实验来验证这一点
将你的批大小从 1 一直增大到 GPU 显存允许的上限,在中间至少尝试几个不同的批大小,包括常见的取值如 64 和 128
Deliverable:不同批大小下训练运行的学习曲线,如有必要,应重新调优学习率
Deliverable:用几句话总结你在批大小变化方面的实验发现,以及它们对训练过程的影响
实验设置
在本实验中,博主固定了模型结构与优化器配置,并使用在学习率实验中确定的稳定学习率区间(lr_max=1e-3, lr_min=1e-4)。由于硬件显存限制,单卡环境下可支持的最大 batch size 为 12,因此本实验在 batch_size = {1,2,4,8,12} 的范围内进行对比
所有实验使用相同的训练步数预算(max_steps=3000, warmup_iters=200),并记录训练损失与验证损失随梯度更新步数的变化曲线
batch size 扫描脚本如下:
import gc
import time
import torch
from typing import Sequence
import cs336_basics.config as config_mod
import cs336_basics.train as train_mod
def run_one(batch_size: int, tag: str = "") -> None:
"""
Run one training job by patching train.get_default_config() to return
a config with a fixed LR and varying batch size.
"""
cfg = config_mod.get_default_config()
# ---- fixed LR (from your LR sweep result) ----
cfg.optim.lr_max = 1e-3
cfg.optim.lr_min = 1e-4
# ---- variable: batch size ----
cfg.train.batch_size = int(batch_size)
# short sweep run (keep cost low)
cfg.train.max_steps = 3000
cfg.optim.warmup_iters = 200
cfg.optim.cosine_cycle_iters = 3000
cfg.train.eval_interval = 500
# name = bs only (single variable!)
cfg.run.run_name = f"bs{batch_size}{('_' + tag) if tag else ''}"
# cfg.wandb.enable = False
# ---- patch train_mod.get_default_config ----
def _patched_get_default_config():
return cfg
train_mod.get_default_config = _patched_get_default_config
print("
" + "=" * 80)
print(
f"[SWEEP] start run: "
f"batch_size={cfg.train.batch_size} "
f"lr_max={cfg.optim.lr_max} "
f"run_name={cfg.run.run_name}"
)
print("=" * 80)
train_mod.main()
# cleanup
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def main(batch_sizes: Sequence[int]) -> None:
t0 = time.time()
for bs in batch_sizes:
run_one(bs, tag="batch_sweep")
dt = time.time() - t0
print(f"
[SWEEP] all done. total wall time: {dt/60:.1f} min")
if __name__ == "__main__":
# Given your hardware limit
batch_sizes = [1, 2, 4, 8, 12]
main(batch_sizes)
执行 uv run scripts/sweep_batch.py 指令后输出如下图所示:

我们可以把不同 batch size 训练下的损失曲线绘制在一起,如下图所示:

实验结果与观察
从训练与验证曲线我们可以观察到以下现象:
1. 过小的 batch size 会显著降低训练稳定性
当 batch size 较小(如 bs=1 或 bs=2)时,训练损失曲线呈现出明显更大的波动,反映出梯度估计噪声较大;验证损失下降速度也较慢,在相同步数下明显劣于更大的 batch size
2. 在可测试范围内(bs=1 → 12),增大 batch size 带来更快收敛与更低验证损失
随着 batch size 增大,训练损失曲线逐渐变得更加平滑,验证损失在相同步数下持续降低,其中,bs=8 与 bs=12 的训练过程最为稳定,且最终验证损失最低
3. 当前实验仅覆盖 batch size 提升的初期阶段
需要强调的是,本实验中的 batch size 上限(12)远未达到常见大规模训练中讨论的最优 batch size 或临界 batch size,因此,这里的结论仅适用于 batch size 较小到中等规模的增长阶段
4. 关于更大 batch size 的讨论(推测性分析)
尽管在本实验范围内 batch size 越大表现越好,但已有研究 [Keskar+ 2017] [Goyal+ 2017] 表明,batch size 并非越大越好。当 batch size 继续增大(如 64、128 或更高)时,若不相应调整学习率、warmup 策略或正则化强度,模型可能会出现收敛速度变慢、泛化性能下降等问题,这是因为过大的 batch 会显著降低梯度噪声,可能使优化过程更容易陷入 “尖锐极小值”,从而影响泛化能力
受限于硬件资源,本实验未能直接验证这一阶段,大家如果硬件资源足够的话,可以自己进一步尝试更大的 batch size 进行探索
4. Problem (generate): Generate text (1 point)
在你已经实现了解码器之后,我们现在可以生成文本了!我们将使用训练好的模型进行文本生成,并观察生成效果如何,作为参考,你生成的结果至少应当达到下面示例的质量水平
Example (ts_generate_example): Sample output from a TinyStories language model
Once upon a time, there was a pretty girl named Lily. She loved to eat gum, especially the big black one. One day, Lily’s mom asked her to help cook dinner. Lily was so excited! She loved to help her mom. Lily’s mom made a big pot of soup for dinner. Lily was so happy and said, “Thank you, Mommy! I love you.” She helped her mom pour the soup into a big bowl. After dinner, Lily’s mom made some yummy soup. Lily loved it! She said, “Thank you, Mommy! This soup is so yummy!” Her mom smiled and said, “I’m glad you like it, Lily.” They finished cooking and continued to cook together. The end.
下面是精确的问题说明以及我们对你的要求:
使用你实现的解码器以及你训练好的模型 checkpoint,报告由你的模型生成的文本,你可能需要调整解码器的参数(例如 temperature、top-p 等)才能得到较为流畅的输出
Deliverable:至少 256 个 token 的生成文本(或者直接首次生成 <|endoftext|> token 为止),对生成文本流畅度做简要评价,并解释哪些因素(至少两个)会影响生成文本质量的好坏。
执行 uv run cs336_basics/generate.py 指令后输入如下所示:

生成文本(sampling)的设置如下:
- Prompt:Once upon a time
- Checkpoint:博主在学习率实验长步数训练、验证损失最低的 best checkpoint
- Decoding:
max_new_tokens=128temperature=1.0top_p=0.9
生成文本节选:
Once upon a time, there was a thin cat named Fluffy. Fluffy liked to play outside in the sun. One day, Fluffy saw a big bird in the sky. The bird had many colors on its wings.
Fluffy said, “Hello, bird! I like your colors. Can we be friends?” The bird smiled and said, “Yes, we can be friends, Fluffy!”
So, Fluffy and the bird played together every day. They played catch, chase, and hide-and-seek. Fluffy and the bird were very happy. They loved their new friend and had lots of fun together.
<|endoftext|>
博主生成的这段文本整体 非常流畅,基本符合 TinyStoires 的简单故事风格:
- 语法与句子结构正确:几乎没有断句或乱码式的无意义短语
- 实体与情节一致性好:Fluffy(猫)与 bird 的关系贯穿全文,没有突然换主角或逻辑断裂
- 故事结构完整:介绍主角 → 发生事件(遇到鸟)→ 对话建立关系 → 一起玩耍 → 正向收尾,并能自然输出
<|endoftext|>结束
当然也有一些小瑕疵,比如 “thin cat” 这种形容略奇怪,但不影响整体可读性
我们可以来看下解码参数 temperature 以及 top_p 的变化对最终结果会产生什么影响:
解码参数:
temperature=0.7top_p=0.9
生成文本节选:
Once upon a time, there was a little girl named Lucy. She had a big, soft mattress that she loved to jump on. One day, Lucy wanted to show her friends her mattress. She was very excited to show them her new mattress.
Lucy’s friends came over to her house. They saw the mattress and thought it was very nice. They all wanted to jump on it. Lucy was a little nervous, but she wanted to show her friends.
Lucy and her friends took turns jumping on the mattress. They laughed and had so much fun. When it was time to go home, Lucy’s mom said, "I recommend we take a
从上面生成的文本中我们可以知道较低的 temperature 会使模型更倾向于选择高概率 token,生成结果更加稳定、保守,故事连贯性较强,但在内容上略显重复,创造性有所降低
解码参数:
temperature=1.2top_p=1.0
生成文本节选:
Once upon a time, there lived an ancient dolphin named Dolly. Dolly was very old and tried to swim fast. She wanted to see whose night went up in the sky like that one day wake up, so she jumped up and started searching.
The smell of wisdom filled the air filled the air little upon loved Pinky. Embarrassed, she stayed– secrets to cover her body and swam faster. After a long hard duck searching, she was reunited with her friends alert.
Then, suddenly, Abigail caught sight behind her wings and snuggled into the softest velvet feet. Everything between her teeth - birds and grass were mommy’s bund
而较高的 temperature 以及未限制的 top-p 显著增加了采样的随机性,虽然文本多样性提高,但语义连贯性明显下降,出现了句子断裂、语义混乱以及重复片段,体现了过度随机采样带来的负面影响
我们再来看下未经充分训练的模型生成的文本怎么样:
生成文本(sampling)的设置如下:
- Prompt:Once upon a time
- Checkpoint:博主在学习率实验仅训练 3000 步的模型
- Decoding:
max_new_tokens=128temperature=1.0top_p=0.9
生成文本节选:
Once upon a time, there was a little bird who lived in the garden. He liked to look around the trees and watch the clouds on it. He also wanted to show his friend, the lion, and play some beef. The strawberry was blue and tall. The ice cream said “No, it’s too! You can play too!”
The lion and the little mouse ran off to the brave boat, but he saw a bright glass that was thinking. It was very happy. He could sing and told the pepper to attach the glowing one away.
<|endoftext|>
可以看到,与经过长步数训练后的模型相比,该模型生成的文本在整体流畅性与语义一致性存在明显不足。虽然生成的文本在句法层面仍能形成基本的英文句子结构,但在语义连贯性和实体一致性方面问题较为突出,具体表现为:
- 语义跳跃严重:文本中角色与物体之间的关系缺乏合理过渡,例如鸟、狮子、冰淇淋等实体随机出现,情节缺乏因果逻辑,故事难以形成连贯叙事
- 概念混淆与不合理组合:出现了 “The ice cream said…” 等明显不符合常识或上下文的描述,说明模型尚未学会稳定的语义约束
- 角色指代混乱:代词(he/it)的指代对象频繁变换,导致读者难以判断当前叙事主体,体现出模型在长距离依赖建模上的不足
通过上述对比实验,我们可以总结出以下几个影响文本生成质量的重要因素:
1. Temperature 参数
Temperature 控制 logits 分布的平滑程度:
- 较低 temperature(如 0.7)使模型更偏向高概率词,生成稳定但略显保守
- 较高 temperature(如 1.2)增强多样性,但容易引入语义噪声,导致文本不连贯
2. Top-p(Nucleus Sampling)
Top-p 决定了参与采样的概率质量范围:
- 合理的 top-p(如 0.9)能够过滤极低概率 token,提高生成流畅度
- 当 top-p = 1.0 时,模型可能采样到长尾分布中的低质量 token,从而破坏整体语义结构
3. 模型训练充分程度
在实验中,使用经过长时间训练、验证集损失较低的模型 checkpoint,可以显著改善生成文本的语法正确性与故事连贯性,相同的解码参数在训练不足的模型上通常会产生重复或无意义的输出
5. Problem (layer_norm_ablation): Remove RMSNorm and train (1 point) (1 H100 hr)
Ablation 1: layer normalization
人们常说,层归一化(layer normalization)对于 Transformer 训练的稳定性至关重要,不过,我们不妨冒点险:将每个 Transformer 模块中的 RMSNorm 移除,看看会发生什么
从你的 Transformer 中 移除所有 RMSNorm,然后重新训练模型,在之前的最优学习率下会发生什么?是否可以通过 降低学习率 来恢复训练稳定性?
Deliverable:在最佳学习率下移除 RMSNorm 后训练得到的学习曲线。
Deliverable:用几句话总结 RMSNorm 对模型训练的影响。
代码修改比较简单,我们可以直接用一个线性 Norm 来替代 RMSNorm:
A) 在 modules.py 里加一个 IdentityNorm
class IdentityNorm(nn.Module):
"""Drop-in replacement for RMSNorm that does nothing."""
def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype=None):
super().__init__()
def forward(self, x):
return x
B) 在 modules.py 的 TransformerBlock 里替换 ln1/ln2
# self.ln1 = RMSNorm(...)
# self.ln2 = RMSNorm(...)
self.ln1 = IdentityNorm(self.d_model, eps=eps, device=device, dtype=dtype)
self.ln2 = IdentityNorm(self.d_model, eps=eps, device=device, dtype=dtype)
C) 在 transformer_lm.py 里替换 ln_final
from cs336_basics.modules import IdentityNorm
# self.ln_final = RMSNorm(...)
self.ln_final = IdentityNorm(self.d_model, eps=eps, device=device, dtype=dtype)
博主将 modules.py 以及 transformer_lm.py 中的所有 RMSNorm 移除后在最佳学习率下训练得到的学习曲线如下图所示:

从上图可以看出,在保持其余配置不变,直接移除所有 RMSNorm 并使用 baseline 的最优学习率 lr_max=1e-3 训练时,训练曲线表现出明显的数值不稳定:train/loss 出现极端峰值(从正常量级突然飙升到非常夸张的数值),这是典型的梯度/激活时空或数值溢出信号
博主尝试降低学习率(lr_max=5e-4, lr_min=5e-5)后训练得到的学习曲线如下图所示:

可以看到,当我们将学习率降低到 lr_max=5e-4 后(其余设置保持不变),train/loss 变得平滑且持续下降,不再出现前面那种灾难级尖峰,这说明,降低学习率确实可以显著恢复无 RMSNorm 模型的训练稳定性,换句话说,移除 RMSNorm 后模型的 “可用学习率上限” 被明显压低
通过上面的实验,我们可以简单概括性 RMSNorm 对训练的影响:
- 稳定性方面:RMSNorm 的主要作用之一是控制每层输入的尺度,减少激活/梯度在深层网络中的累积放大,移除 RMSNorm 后,训练更容易出现梯度爆炸或数值不稳定
- 可用学习率方面:有 RMSNorm 时模型可以承受更大的学习率,没有 RMSNorm 时,为了避免发散,需要明显降低学习率
- 收敛效率方面:在相同训练步数预算下,RMSNorm 往往能让训练更 “省心”:允许使用更激进的学习率、更快下降且更少异常波动,无 RMSNorm 虽然也能收敛,但通常需要更保守的 LR 才能维持稳定
6. Problem (pre_norm_ablation): Implement post-norm and train (1 point) (1 H100 hr)
接下来,我们研究另一种乍看之下有些随意,但实际上影响很大的层归一化设计选择
Pre-Norm Transformer 的定义如下:
z = x + MultiHeadedSelfAttention ( RMSNorm ( x ) ) y = z + FFN ( RMSNorm ( z ) ) z = x + ext{MultiHeadedSelfAttention}( ext{RMSNorm}(x)) y = z + ext{FFN}( ext{RMSNorm}(z)) z=x+MultiHeadedSelfAttention(RMSNorm(x))y=z+FFN(RMSNorm(z))
这是对原始 Transformer 架构为数不多、已形成共识的修改之一
而原始 Transformer 使用的是 Post-Norm 形式:
z = RMSNorm ( x + MultiHeadedSelfAttention ( x ) ) y = RMSNorm ( z + FFN ( z ) ) z = ext{RMSNorm}(x + ext{MultiHeadedSelfAttention}(x)) y = ext{RMSNorm}(z + ext{FFN}(z)) z=RMSNorm(x+MultiHeadedSelfAttention(x))y=RMSNorm(z+FFN(z))
现在,让我们把模型改回 Post-Norm 架构,看看会发生什么
将你当前的 Pre-Norm Transformer 实现修改为 Post-Norm,使用 Post-Norm 模型进行训练,并观察其行为
Deliverable:Post-Norm Transformer 的学习曲线,与 Pre-Norm Transformer 学习曲线的对比分析。
代码修改比较简单,我们直接修改 modules.py 中的 TransformerBlock 的 forward 部分就行:
# Pre-norm attention + residual
# h = self.ln1(x)
# x = x + self.attn(h, token_positions)
# Pre-norm FFN + residual
# h = self.ln2(x)
# x = x + self.ffn(h)
# Post-norm
x = self.ln1(x + self.attn(x, token_positions))
x = self.ln2(x + self.ffn(x))
博主使用 Post-Norm 模型在最佳学习率下训练得到的学习曲线如下图所示:

从图中我们可以看到,Post-Norm Transformer 在训练初期表现出更差的稳定性,训练损失下降更慢且波动更大;在验证集上,其收敛速度与最终性能也略逊于 Pre-Norm 架构。这说明层归一化不仅是否存在很重要,其放置位置同样对优化行为具有决定性影响,Pre-Norm 通过将归一化放置在子模块之前,使梯度能够更直接地通过残差路径传播,从而显著改善了训练稳定性与优化效率
7. Problem (no_pos_emb): Implement NoPE (1 point) (1 H100 hr)
Ablation 2: position embeddings
接下来,我们将研究 位置嵌入对模型性能的影响,具体来说,我们会比较以下两种模型:
- 使用 RoPE 的基础模型
- 完全不使用位置嵌入 的模型(NoPE)
事实表明,仅解码器(decoder-only)的 Transformer,也就是说,像我们实现的这种带因果掩码的模型,在理论上 即使不显式提供位置嵌入,也能够推断出相对或绝对的位置信息 [Tsai+ 2019] [Kazemnejad+ 2023]
接下来,我们将通过实验来实证比较 NoPE 与 RoPE 的表现差异
修改你当前使用 RoPE 的 Transformer 实现,完全移除所有位置嵌入相关的信息,重新训练模型,并观察训练过程和结果会发生什么变化。
Deliverable:一条对比 RoPE 与 NoPE 性能的学习曲线。
代码修改如下:
A) 在 modules.py 的 TransformerBlock 里使用不带 RoPE 的因果注意力头
def __init__(...):
# self.attn = CausalMultiHeadSelfAttentionWithRoPE(
# d_model=self.d_model,
# num_heads=self.num_heads,
# theta=theta,
# max_seq_len=max_seq_len,
# device=device,
# dtype=dtype
# )
self.attn = CausalMultiHeadSelfAttention(
d_model=d_model,
num_heads=num_heads,
device=device,
dtype=dtype
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Pre-norm attention + residual
h = self.ln1(x)
# x = x + self.attn(h, token_positions)
x = x + self.attn(h)
B) 在 transformer_lm.py 中不再传入 token_positions
def forward(self, in_indices: torch.Tensor) -> torch.Tensor:
# Token positions for RoPE: (batch, seq_len)
# token_positions = torch.arange(seq_len, device=in_indices.device, dtype=torch.long).view(1, seq_len)
# token_positions = token_positions.expand(batch, seq_len)
# Embed tokens: (batch, seq_len, d_model)
x = self.token_embeddings(in_indices)
# Apply Transformer blocks
for block in self.layers:
# x = block(x, token_positions)
x = block(x)
博主将 modules.py 以及 transformer_lm.py 中的所有位置嵌入信息(RoPE)移除后在最佳学习率下训练得到的学习曲线如下图所示:

从训练曲线可以看出,NoPE 模型依然能够稳定训练,其训练损失随步数持续下降,并未出现梯度爆炸或数值不稳定现象,但 NoPE 的验证损失全程高于 RoPE,表明其对序列结构的泛化能力明显不足,RoPE 模型在学习效率和最终性能上均占据优势,显示出显式位置建模对语言建模任务仍然具有重要作用
总体而言,本实验表明,位置嵌入并非 Transformer 正常训练的必要条件:在 NoPE 设置下,模型仍具备一定的顺序建模能力,这与已有研究中 [Haviv+ 2022] 关于 decode-only Transformer 可隐式推断位置信息的结果一致,但显式的位置嵌入(如 RoPE)为模型提供了更强的序列归纳偏置,能够显著提升训练效率和最终性能
8. Problem (swiglu_ablation): SwiGLU vs. SiLU (1 point) (1 H100 hr)
Ablation 3: SwiGLU vs. SiLU
接下来,我们将遵循 [Shazeer] 的工作,通过比较 SwiGLU 前馈网络 与 使用 SiLU 激活但不带门控线性单元(GLU)的前馈网络,来测试前馈网络中门控机制的重要性:
F F N S i L U ( x ) = W 2 S i L U ( W 1 x ) . (25) mathrm{FFN}_{mathrm{SiLU}}(x) = W_2 mathrm{SiLU}(W_1 x). ag{25} FFNSiLU(x)=W2SiLU(W1x).(25)
回顾我们在 SwiGLU 中的实现方式,我们将前馈网络内部隐藏层的维度设置为 d ff = 8 3 d model d_{ ext{ff}}= rac{8}{3}d_{ ext{model}} dff=38dmodel,并同时确保 d ff d_{ ext{ff}} dff 是 64 的倍数,以便更好地利用 GPU Tensor Core
而在 FFN_SiLU 的实现中,你应当将 d ff = 4 × d model d_{ ext{ff}}=4 imes d_{ ext{model}} dff=4×dmodel,以便在参数数量上近似匹配 SwiGLU 前馈网络,因为 SwiGLU 使用的是三个权重矩阵,而非两个
Deliverable:给出一条学习曲线,对比 SwiGLU 前馈网络与 SiLU 前馈网络在参数规模近似匹配条件下的性能表现。
Deliverable:用几句话总结并讨论你的实验发现。
代码修改如下:
A) modules.py 新增一个 FFNSiLU 类
class FFNSiLU(nn.Module):
"""
Position-wise feed-forward network with SiLU activation (no gating).
FFN_SiLU(x) = W2(SiLU(W1 x))
Shapes:
input: (..., d_model)
W1: (d_ff, d_model)
W2: (d_model, d_ff)
output: (..., d_model)
"""
def __init__(
self,
d_model: int,
d_ff: int,
device: torch.device | None = None,
dtype: torch.dtype | None = None,
):
super().__init__()
self.d_model = int(d_model)
self.d_ff = int(d_ff)
self.w1 = Linear(self.d_model, self.d_ff, device=device, dtype=dtype)
self.w2 = Linear(self.d_ff, self.d_model, device=device, dtype=dtype)
@staticmethod
def silu(x: torch.Tensor) -> torch.Tensor:
return x * torch.sigmoid(x)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.w2(self.silu(self.w1(x)))
B) 修改 TransformerBlock 类,将 self.ffn 从 SwiGLU 替换为 FFNSiLU
# self.ffn = SwiGLU(self.d_model, d_ff=self.d_ff, device=device, dtype=dtype)
self.ffn = FFNSiLU(self.d_model, d_ff=self.d_ff, device=device, dtype=dtype)
C) 修改 config.py 中的 d_ff,从 1344 修改为 2048
# If None, will default to 4 * d_model at model construction time
d_ff: Optional[int] = 2048
博主将 SwiGLU 前馈网络替换为 SiLU 前馈网络后在最佳学习率下训练得到的学习曲线如下图所示:

从训练损失曲线可以观察到,两种模型在训练初期都能稳定收敛,且整体下降趋势相似,但 SwiGLU 在整个训练过程中始终保持略低于 SiLU 的训练损失,同时曲线波动也略小,表现出更平滑的优化轨迹,这表明门控机制在前馈网络中有助于改善梯度传播与特征调制,使优化过程更加稳定
在验证集上,这一差异更加清晰,SwiGLU 模型在几乎所有训练阶段都取得了更低的验证损失,尽管两者的最终验证损失差距较小,但 SwiGLU 始终占据上风,说明在相近参数规模下,引入门控可以带来更好的泛化性能
综合来看,该实验验证了 [Shazeer] 等人提出的结论:前馈网络中的门控结构(如 SwiGLU)并非只是参数重排,而是能够显著提升模型的表达能力与训练效果
8. Problem (main_experiment): Experiment on OWT (2 points) (3 H100 hrs)
使用与 TinyStories 实验 相同的模型结构和相同的总训练迭代次数,在 OpenWebText(OWT) 数据集上训练你的语言模型,模型在 OpenWebText 上的表现如何?
Deliverable:提交你的语言模型在 OpenWebText 上训练得到的学习曲线,描述与 TinyStories 相比,损失值有哪些不同?我们应当如何理解这种差异?
Deliverable:给出在 OpenWebText 上训练得到的语言模型生成的文本,格式需与 TinyStories 的生成结果一致。讨论生成文本的流畅度如何?尽管使用了与 TinyStories 相同的模型结构和计算预算,为什么在 OpenWebText 上生成的文本质量仍然更差?
博主将数据集替换为 OpenWebText 在相同模型参数配置下训练得到的学习曲线如下图所示:

Note:由于词表规模(32,000)和显存限制,OpenWebText 实验使用了更小的 batch size(batch_size=6),这使得上面两组实验其实并非完全对等,但训练曲线所呈现出的显著差异仍然可以清楚地反映出不同数据分布在语言建模难度上的本质区别
从训练与验证损失曲线我们可以观察到 OpenWebText 相比于 TinyStories 的显著区别是:在 TinyStories 上,模型的 训练损失和验证损失下降得更快、最终收敛到显著更低得数值;而在 OpenWebText 上,无论是训练集还是验证集,损失整体都 显著提高,且下降速度更慢,即使在训练后期也仍维持在较高水平
这一差异并不意味着模型 “训练失败”,而是 反映了数据分布本身的难度差异,TinyStories 是经过精心构造的、词汇和句式都极度受限的儿童故事语料,具有 低困惑度、强局部模式、长程依赖弱 的特点,非常容易被小模型快速拟合。相比之下,OpenWebText 来自真实互联网文本,包含新闻、评论、技术文章、叙事性文本等多种风格,词汇表更大、语义更复杂、上下文依赖更长且更弱规则化,在相同模型容量和训练预算下,自然会表现出更高的损失
因此,更高的 loss 并不代表训练效果更差,而是说明任务本身更困难
利用训练好的 OpenWebText 模型执行 uv run cs336_basics/generate.py 后输出如下图所示:

Note:博主使用的提示词是 In today’s article, we take a closer look at
生成的文本如下:
In today’s article, we take a closer look at how technologies are actually useful for our approach:
Turn around and edit devices!
Apple Wi-Fi
(RESY) Yes, there’s still a minimum of computer running devices (North or Eastern) with no bands (UPF) You can’t easily find the connectivity to fit your personal phone. Put as many computers, local devices are on the rise to drive prices (a few of them don’t even offer good reason)
A certain HPA is the console’s claps (sound of people and devices) though it’s not terribly important to own systems to connect them, either. A physical
从生成的文本我们可以观察到如下现象:
- 生成文本在 局部层面是流畅的:语法大体正确、句子形式合理,看起来像 “真实网页文本”
- 但在 全局结构和语义连贯性上明显不足:主题频繁跳跃,段落组织松散,内容容易出现半途而废或逻辑断裂
- 与 TinyStories 模型相比,可读性和叙事完整性反而更差
这背后的原因同样与数据分布和训练规模密切相关:TinyStories 的文本模式高度统一,模型只需要学会少量模板化叙事结构即可生成看起来很好的故事;而 OpenWebText 数据噪声大,它要求模型同时掌握事实性表述、抽象概念、长距离依赖、篇幅结构等能力,这些都需要 更大的模型容量或更长的训练时间
在本实验中,我们刻意使用了与 TinyStories 完全相同的模型结构和计算预算,在这 OWT 场景下是 明显欠参数化和欠训练的,模型能够学到局部语言统计特性,但不足以建模高层语言和篇章结构
总的来说,在相同模型结构和训练预算下,OpenWebText 相比 TinyStories 表现出更高的训练与验证损失,且生成文本在全局连贯性上明显更弱。这一结果并非模型退化,而是源于真实网络语料在词汇规模、语义复杂度和长程依赖上的显著提升,这也说明在更复杂数据分布上获得高质量生成能力必须依赖更大的模型规模和更长的训练过程
9. Problem (leaderboard): Leaderboard (6 points) (10 H100 hrs)
你需要在上述排行榜规则约束下训练一个模型,目标是在 1.5 小时的 H100 训练时间内,尽可能降低语言模型在验证集上的损失
Deliverable:记录的最终验证损失值,一条对应的学习曲线,其横轴清晰展示 wall-clock 时间,且不超过 1.5 小时,对你所做修改的简要说明,我们期望排行榜提交的结果至少小于原始基线模型的 5.0 loss,请将你的结果提交到以下排行榜页面:https://github.com/stanford-cs336/assignment1-basics-leaderboard
Note:对于打榜大家如果有想法的话可以自己试试,这里博主就跳过了
博主在当前硬件资源的模型参数配置下尝试了作业推荐的一个优化:引入了输入嵌入与输出 LM head 的权重共享(weight tying),主要修改点如下:
A) 在 transformer_lm.py 的 TransformerLM 类的初始化中加上 weight tying
# transformer_lm.py
self.token_embeddings = Embedding(self.vocab_size, self.d_model, device=device, dtype=dtype)
...
self.lm_head = Linear(self.d_model, self.vocab_size, device=device, dtype=dtype)
# weight tying: share parameters
del self.lm_head._parameters["weight"]
self.lm_head.weight = self.token_embeddings.weight
B) 把 embedding 初始标准差调小一点
self.token_embeddings = Embedding(self.vocab_size, self.d_model, device=device, dtype=dtype)
# after creating token_embeddings
nn.init.trunc_normal_(self.token_embeddings.weight, mean=0.0, std=0.02, a=-0.06, b=0.06)
修改后的训练曲线与 Baseline 对比如下图所示:

从训练与验证曲线可以观察到,在完全相同的训练预算下,引入 weight typing 后的模型在 整个训练过程中均表现出更低的训练损失与验证损失,尤其是在中后期阶段,优化模型的验证损失曲线整体下移,最终验证 loss 相比基线模型有一个 稳定而一致的改善,这表明该修改在当前小模型与小 batch 的设置下是有效的,大家感兴趣的可以自己试试
OK,以上就是本次 Experiments 作业的全部实现了
值得注意的是,受限于个人硬件条件以及时间精力,本次实验小节博主其实做得还远远不够,上面展示的结果大部分是在固定模型规模和有限预算下展开的,对一些关键架构设计选择和消融方向做的验证性实验非常有限,如果大家拥有更充足的硬件资源和时间,可以进一步扩展并尝试更多方向🤗
结语
本篇文章我们完成了 CS336 Assignment 1 中 Experiments 部分的全部实现与实验分析,从最基础的实验记录系统搭建开始,逐步完成了学习率与 batch size 的系统扫描,并围绕归一化方式、位置嵌入、前馈网络结构等关键设计选择,进行了多组具有代表性的消融实验,最后将模型迁移到 OpenWebText 数据集上进行训练与生成测试
与跑通一个模型相比,本小节更重要的收获在于:通过真实训练曲线与生成结果,建立了对 Transformer 行为的经验性认知。例如,最优学习率往往位于稳定性边缘、RMSNorm 与 Pre-Norm 对可用学习率上限的决定性影响、显式位置嵌入对训练效率与泛化能力的贡献,以及门控前馈结构在相近参数规模下带来的稳定收益,这些结论都只有在完整训练与对比实验中才会清晰可见
同时,TinyStories 与 OpenWebText 的对比实验也直观地揭示了数据分布复杂度对语言建模难度的本质影响:在相同模型规模和训练预算下,更高的 loss 与更差的生成质量并不意味着训练失败,而是反映了真实网络语料在词汇规模、语义多样性与长程依赖上的显著提升,这也说明,高质量的生成能力必须依赖更大的模型容量和更长的训练过程
需要坦率说明的是,受限于博主个人硬件条件与可投入的时间精力,本文中的实验更多是验证性与探索性的,而非对最优配置的系统性搜索或充分打榜尝试
至此,我们完成了 Assignment 1: Basics 中要求的所有作业,下篇文章开始我们将进入 Assignment 2: Systems 的实现,敬请期待🤗
源码下载链接
- https://github.com/Melody-Zhou/stanford-cs336-spring2025-assignments
参考
- https://github.com/stanford-cs336/assignment1-basics
- https://github.com/donglinkang2021/cs336-assignment1-basics
- https://github.com/Louisym/Stanford-CS336-spring25