2025_NIPS_KnowMol: Advancing Molecular Large Language Models with Multi-Level Chemical Knowledge
文章核心总结与创新点
主要内容
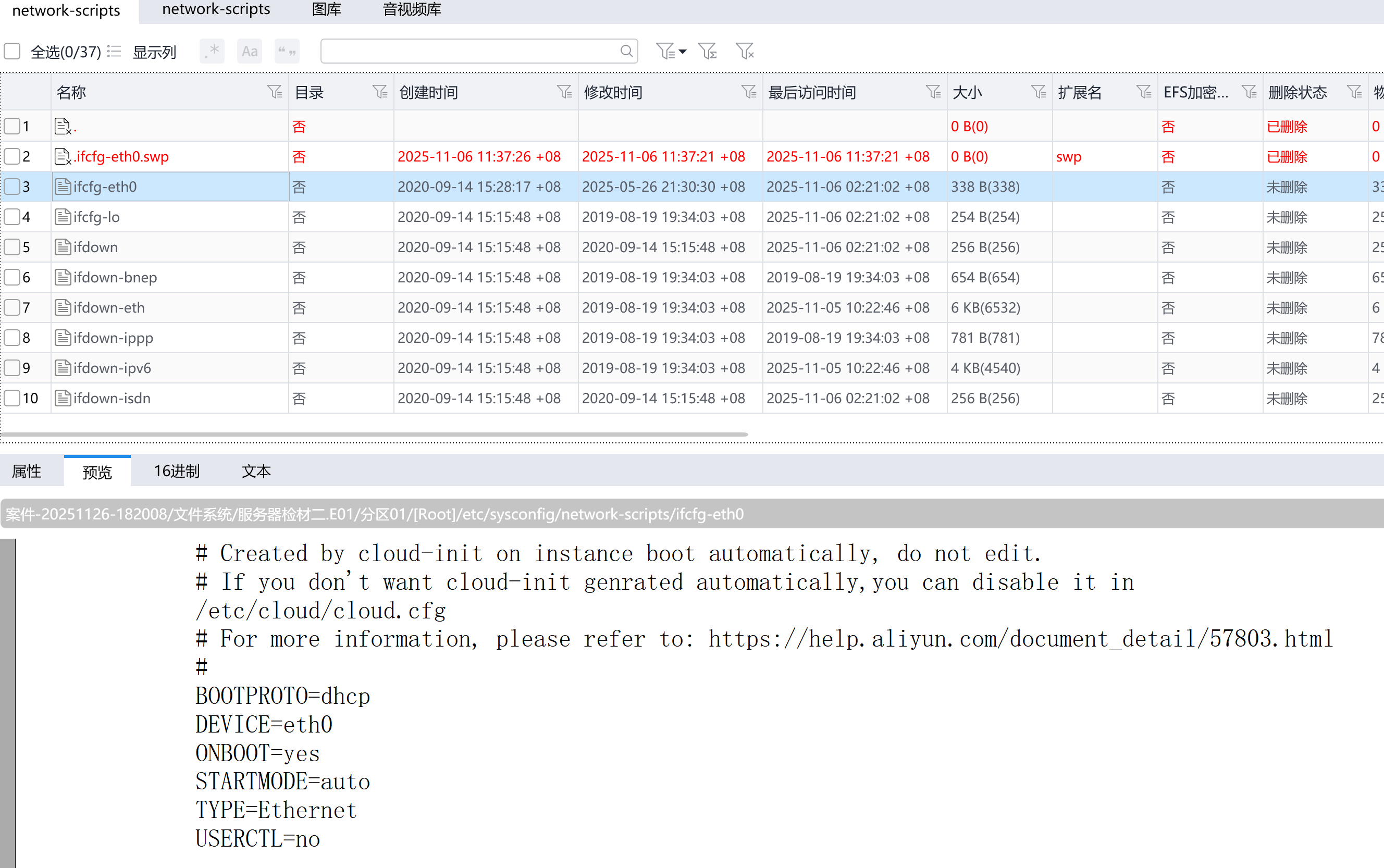
该研究聚焦分子大语言模型(Mol-LLMs)的核心局限,提出了数据集与表征策略的双重创新,最终开发出性能领先的多模态分子大语言模型KnowMol。研究首先指出当前Mol-LLMs因预训练数据集质量不足(PubChem覆盖失衡、粒度粗糙)和分子表征策略欠佳(1D/2D模态信息编码低效),在分子原子识别、官能团鉴定、结构解析和性质预测等基础任务中存在明显缺陷;随后构建了包含10万条多级别分子标注的KnowMol-100K数据集,并设计了化学信息增强的分子表征方案;基于上述创新,通过两轮指令微调训练出KnowMol模型,在分子理解(标注生成、性质预测)和分子生成(反应预测、逆合成分析)7类下游任务中均超越现有模型。
核心创新点
- 数据集创新:构建KnowMol-100K数据集,涵盖原子、官能团、结构构建、理化性质四个层级的精细标注,解决了PubChem数据集覆盖不均衡、描述粗粒度的问题,大幅提升分子信息的完整性和深度。
- 表征策略创新:提出化学信息增强的分子表征方案,1D层面用SELFIES替代SMILES并设计专属词汇表避免模态混淆,2D层面设计层级图编码器,通过局部/全局池化生成原子、官能团、分子三级令牌,高效捕捉分子层级结构信息。
- 模