


机器学习入门01——经典的KNN算法,有讲解有案例,一篇学懂KNN算法。
这里是机器学习入门系列的第一篇文章,今天咱们来拆解最经典、最适合小白入门的机器学习算法——KNN(K近邻算法)。
为什么说KNN适合入门?因为它逻辑简单、无需训练、代码易实现,没有复杂的数学推导(小白友好),同时能帮我们快速理解机器学习的核心思路(分类、回归的基本逻辑)。
1.什么是KNN算法?
KNN的全称是K-Nearest Neighbors,翻译过来就是“K个最近的邻居”。它的核心逻辑一句话就能说清:物以类聚,人以群分。
举一个例子:假设我需要卖一栋房子,我不知道这个房子能卖多少钱,但是我可以通过我的邻居的房子来为我这个房子进行估价,当我选我周围三个邻居时(k=3)邻居房价为:180万、190万、170万,那我大概就可以判断我的房价了,那我想更进一步预测我的房价,这时候我选择我周围的7个邻居(k=7),那我就以这7个邻居的房价估计我的房价,这就是KNN的核心思想。
每个邻居就是我们已知的训练样本;
我们想知道自己的房价就是我们要预测的测试样本;
K就是我们选择的“邻居数量”,通过分类问题或回归问题,给测试样本打上标签。

2.KNN算法的核心步骤
KNN算法既可以运用到分类问题,也可以运用到回归问题。
2.1什么是分类问题和回归问题
2.1.1分类
分类的目标是把样本划分到预先定义好的某一个类别中。
比如我们识别图片:猫 / 狗 / 人,将他们分到各自的类别当中。
2.1.2回归
回归的目标是找到输入特征和输出数值之间的数量关系,然后输出的是一个具体的值。
比如:我们根据房子的面积 / 地段,预测房价 85.6 万、92.3 万;
2.2KNN算法步骤
2.2.1数据的预处理
我们训练模型就是要有数据,每个训练样本都包含两个关键信息:特征(比如人的性别、体重,水果的大小、颜色)和标签(比如“身高180”,“性别:男/女”,“红色/黄色”)。
注意:特征必须是“数值型”的(比如身高175cm、体重60kg),如果是文字型(比如“红色”“圆形”),需要先转换成数值类型;另外,不同特征的量级要统一,否则会影响距离计算的准确性(后续会用标准化来处理)。
2.2.2选择KNN算法的k值
K是我们手动设定的“邻居数量”,比如K=3、K=5、K=10,不同的K值会导致不同的预测结果,这也是KNN唯一的核心参数。k值的选取也有讲究:
K太小:邻居太少,容易受“异常值”影响(比如找1个邻居,刚好这个邻居是个特例,预测就会出错);
K太大:邻居太多,会忽略样本的“局部特征”(比如找100个邻居,不管远近都算,相当于用整体趋势预测,比如你家这块房价高,周围房价低,选取邻居太多导致预测自己的房价更低)。
2.2.3计算距离
KNN的核心逻辑是“找最近的邻居”,那怎么判断两个样本的“远近”?答案是计算特征之间的距离。
2.2.3.1欧式距离
我们最常用的计算方法就是欧式距离,相当于平面上两个点的直线距离。
二维空间:a点为(x1,y1),b点为(x2,y2)

三维空间:a点为(x1,y1 ,z1),b点为(x2,y2 ,z2)

n维空间:a点为(x11,x12 ,…,x1n),b点为(x21,x22,…,x2n)

公式不用死记硬背,Python会自己帮忙算的
2.2.3.2曼哈顿距离
相当于“走格子”的距离(只能横向、纵向走),公式:|x1-x2| + |y1-y2|
二维空间:a点为(x1,y1),b点为(x2,y2)

n维空间:a点为(x11,x12 ,…,x1n),b点为(x21,x22,…
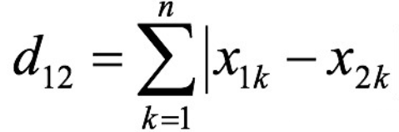
2.2.4得出预测结果
找到最近的K个邻居后,分两种情况:
-
分类问题(比如预测“苹果/橘子”“男/女”):投票,K个邻居中出现次数最多的标签,就是测试样本的预测标签;
-
回归问题(比如预测房价、体重):取平均,K个邻居的标签数值的平均值,就是测试样本的预测值。
3.KNN算法—优缺点
优点:
1.简单,易于理解,易于实现,无需训练;
2.适合对稀有事件进行分类;
3.对异常值不敏感。
缺点︰
1.样本容量比较大时,计算时间很长;
⒉.不均衡样本效果较差;
4.案例实现
现在有很多大学里出现室友矛盾,假如室友可以选择: 大学里面 ,对于校方,把类型相同的学生放在一个寝室,在基于大二大三大四的学生类型建立KNN算法模型,预测大一新生的类型,并将相同类型的学生安排在相同的寝室。
数据文件datingTestSet2.txt ,为历年大学生的调查问卷表
第1列:每年旅行的路程
第2列:玩游戏所有时间百分比
第3列:每个礼拜消耗零食的重量
第4列:学生所属的类别,1表示爱学习,2表示一般般,3表示爱玩。
目的为学生在大学中挑选室友的信息
(我已经将数据文件上传本篇文章)
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
from sklearn.neighbors import KNeighborsClassifier
data01 = np.loadtxt('datingTestSet2.txt')
train_data = data01[:700, :]
test_data = data01[700:, :]
train_X = train_data[:, [0, 1, 2]]
train_y = train_data[:, 3]
test_X = test_data[:, [0, 1, 2]]
test_y = test_data[:, 3]
data = pd.DataFrame()
data['参数1'] = scale(train_X[:, 0])
data['参数2'] = scale(train_X[:, 1])
data['参数3'] = scale(train_X[:, 2])
data_test = pd.DataFrame()
data_test['参数1'] = scale(test_X[:, 0])
data_test['参数2'] = scale(test_X[:, 1])
data_test['参数3'] = scale(test_X[:, 2])
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(data, train_y)
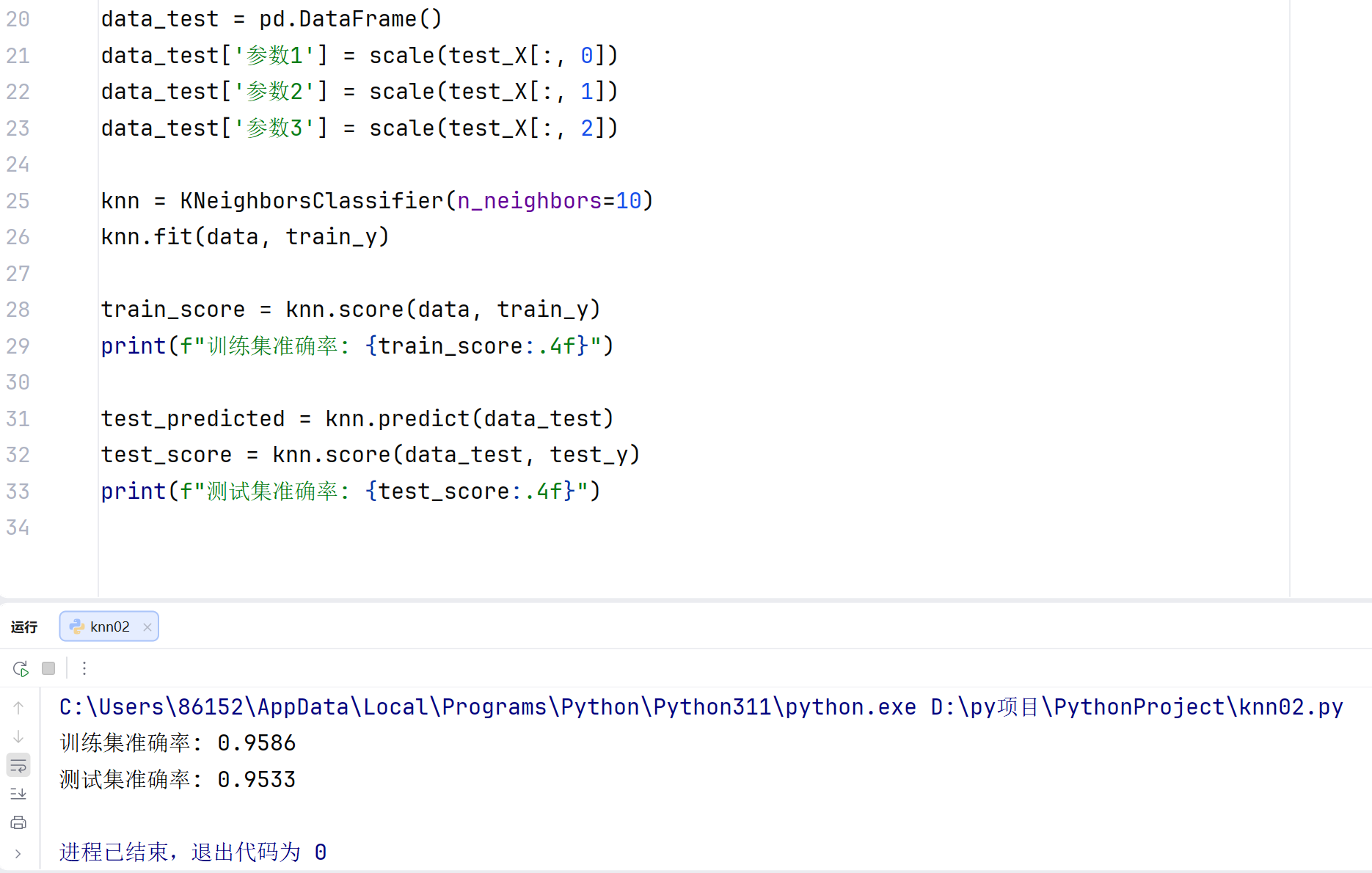
train_score = knn.score(data, train_y)
print(f"训练集准确率: {train_score:.4f}")
test_predicted = knn.predict(data_test)
test_score = knn.score(data_test, test_y)
print(f"测试集准确率: {test_score:.4f}")
数据集部分展示:

运行结果:
代码解析:

先将数据导入data01,然后将数据的前700行作为训练集,后300行作为测试集

训练集、测试集的X为第一列,第二列,第三列,Y为第四列,情请看上面的数据集部分展示图。
参数1、2、3为第一列,第二列,第三列

这行代码就是使用KNN算法,其中K值为10,意思就是选取10个邻居。

之后就是将结果打印输出。
由此可见,KNN算法真的很简单,主要内容就已经介绍完毕。
日记
1月29日,星期四
充电的一天
今天星期四,照例是自习课,早上醒来迷迷糊糊的想再睡一会,然后9点多到自习室,发现来早了就几个人,上午复习了一下机器学习,真的是困得要死,然后下午真撑不住了,悄咪咪的在13:00溜回寝室睡大觉了,睡到16:30一身轻松,晚上又有精力去学习了。
得亏周四是自习,好好给自己冲个电。







