Deepseek新架构:Engram全面解析(论文代码详解)
1.简介
本文提出条件记忆(conditional memory) 作为混合专家模型(MoE)条件计算的补充稀疏轴,通过Engram 模块(现代化 N-gram 嵌入实现 O (1) 查找)优化模型架构,揭示了 MoE 与 Engram 之间的U 形缩放定律,在固定参数和计算量下,将 20%-25% 稀疏参数分配给 Engram 效果最优;Engram-27B(26.7B 参数)在知识检索(MMLU+3.4、CMMLU+4.0)、通用推理(BBH+5.0、ARC-Challenge+3.7)、代码 / 数学(HumanEval+3.0、MATH+2.4)等任务上超越同参数同计算量 MoE 基线,且通过确定性寻址实现主机内存预取,推理开销 < 3%,同时提升长上下文检索性能(MultiQuery NIAH 从 84.2 提升至 97.0)。
-
-
2.论文详解
2.1 简介
稀疏性” 是贯穿生物神经网络(如人脑神经元的稀疏激活)和现代大语言模型(LLMs)的关键设计思路 —— 核心是 “不激活所有参数,仅用部分资源完成任务”,从而在提升模型容量的同时控制计算成本。当前 LLM 中,稀疏性主要通过混合专家模型(MoE) 实现:MoE 将模型拆分为多个 “专家网络”,每个 token 仅激活少数专家(如 Top-6),实现 “参数规模暴涨但计算量不按比例增加”。正因如此,MoE 已成为前沿大模型(如 GPT-4、DeepSeek-V3)的默认架构,支撑模型参数突破千亿、万亿规模。
尽管 MoE 很成功,但文章指出其本质缺陷:语言建模包含两个完全不同的子任务,而 MoE 仅优化了 “动态计算”,忽略了 “静态检索”
- 组合推理(compositional reasoning):需要深度、动态的计算(如数学推导、逻辑链分析),MoE 的条件计算对此很擅长;
- 知识检索(knowledge retrieval):大量文本是 “局部、静态、高度固定的”(如命名实体 “亚历山大大帝”、固定短语 “By the way”、公式化表达),这类内容无需复杂计算,更适合 “直接查找”。
传统 Transformer 的低效之处:标准 Transformer(包括 MoE)没有 “原生知识查找” 的组件,只能用 “计算模拟检索”—— 比如要识别 “戴安娜王妃” 这个多 token 实体,需要消耗前几层的注意力和前馈网络,逐步拼接特征(原文表 3 有具体示例)。这相当于 “用复杂运算重建一个静态表格”,浪费了宝贵的模型深度(本可用于推理)在简单的查找任务上。而传统 N-gram 模型(如 3-gram、4-gram)能高效捕捉这类局部静态依赖,证明 “静态模式适合用查找实现”—— 这为文章的创新提供了灵感。
-
2.2 架构
2.2.1 概述
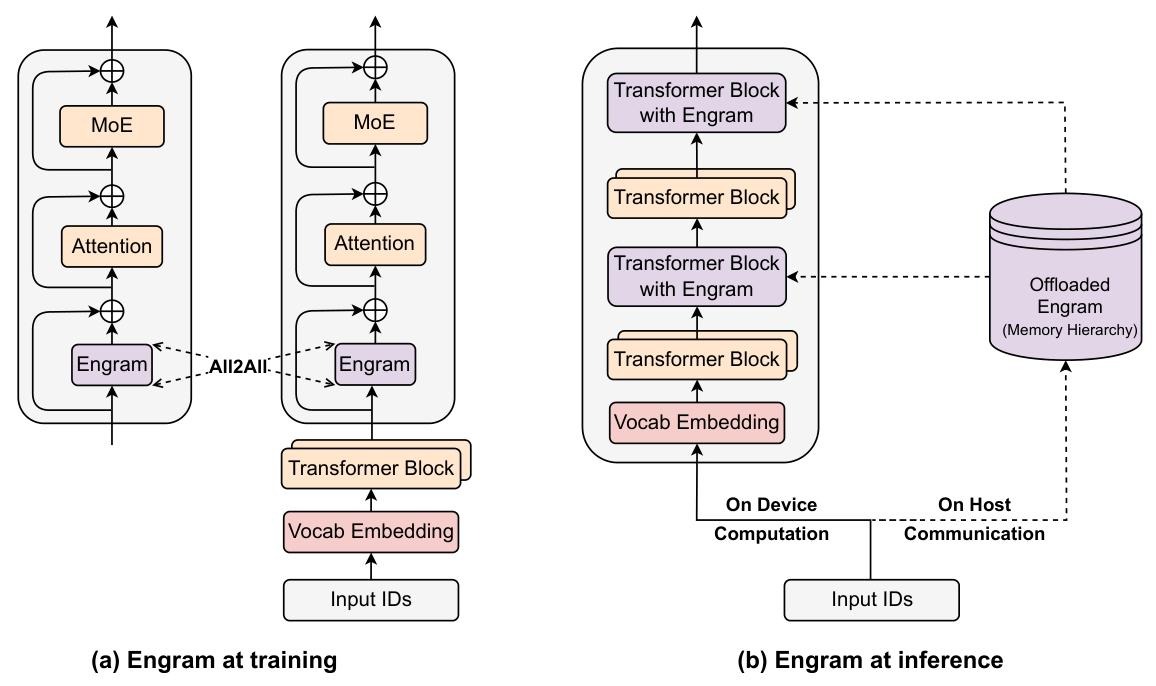
Engram 是一个嵌入 Transformer 中间层的条件记忆模块,核心使命是 “分离静态模式存储与动态计算”—— 不改变 Transformer 的输入嵌入、输出层等核心结构,仅在特定层插入,通过 “检索 + 融合” 两步为每个 token 补充静态知识,再反馈给主干网络。
核心输入与输出
- 输入:① 原始文本序列 X=(x1,...,xT)(T为序列长度);② Transformer 第ℓ层的隐藏状态 H(ℓ)∈RT×d(d为隐藏层维度);
- 输出:融合静态记忆后的优化特征 Y,通过残差连接融入主干:H(ℓ)←H(ℓ)+Y,再进入后续的注意力层和 MoE 层。
三大核心环节
- 检索(Retrieval):从输入序列中提取局部 N-gram,通过哈希查找静态嵌入向量;
- 融合(Fusion):用当前隐藏状态动态调制检索到的静态向量,解决语境适配问题;
- 集成(Integration):适配多分支主干架构,平衡参数效率与表达能力;
- 系统优化(System Design):训练 / 推理阶段的硬件适配,实现计算与内存解耦。

2.2.2 基于哈希N-gram的稀疏检索(Sparse Retrieval via Hashed N-grams)
这是Engram的“记忆提取核心”——解决“如何快速、准确地从海量静态记忆中找到当前token所需的局部模式”,核心是“分词器压缩+多头哈希”,实现O(1)高效检索。
分词器压缩(Tokenizer Compression):减少冗余,提升语义密度
传统子词分词器(如BPE)会给语义相似的token分配不同ID(如“Apple”“apple”“𝜔apple”),导致词汇量冗余,检索效率低。Engram通过“归一化映射”解决:
- 定义满射函数
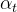 (V为原始词汇表,V' 为规范词汇表);
(V为原始词汇表,V' 为规范词汇表); - 用NFKC标准化、小写化等规则,将原始token ID映射为规范ID(如“Apple”“apple”统一映射为“apple”的规范ID);
- 效果:128k规模的分词器经压缩后,有效词汇量减少23%,既缩小检索范围,又提升语义一致性。
后缀N-gram提取:锁定局部静态模式
对每个位置 t 的规范ID ,提取“后缀N-gram”——即包含当前token在内的前 n-1 个token组成的序列(如 n=2 时为 ,n=3 时为 )。
语言中的静态模式(命名实体、固定短语)多为连续token序列,后缀N-gram能精准捕捉这类局部依赖。
多头哈希(Multi-Head Hashing):快速定位+抗冲突
直接存储所有N-gram组合不现实(如3-gram组合数可达),Engram用“哈希映射”实现高效检索,同时用“多头”避免冲突:为每个N-gram阶数 n(如2-gram、3-gram)配置 K 个独立哈希头; 每个哈希头 k 通过确定性函数(轻量级乘法-XOR哈希),将N-gram 映射为嵌入表 的索引 ;然后从嵌入表中提取向量:(嵌入表大小设为质数,进一步降低冲突概率)。
生成最终记忆向量
将所有N-gram阶数、所有哈希头的嵌入向量拼接,得到当前token的静态记忆向量 : ,用于整合多尺度局部信息(2-gram捕捉短短语,3-gram捕捉长实体),为后续融合提供丰富的静态知识。
-
2.2.3 上下文感知门控(Context-aware Gating)
检索到的静态向量存在“语境不匹配”和“哈希冲突”问题,上下文感知门控是Engram的“智能筛选核心”——用当前隐藏状态动态调节静态记忆的权重,实现“有用则激活,无用则抑制”。
模仿注意力的“动态评估”:
- 静态记忆向量 :作为“待评估的参考答案”;
- 当前隐藏状态 :作为“评估标准”(已包含全局上下文);
- 门控值:作为“评估分数”,控制静态记忆的注入强度。
具体实现步骤
- 投影映射:适配语义空间 将静态记忆向量 投影为Key和Value(类似注意力的QKV拆分),确保与隐藏状态兼容:
- 归一化与相似度计算:稳定数值,评估匹配度 - 对 和 分别做RMSNorm归一化(轻量化,避免梯度爆炸);然后计算两者语义相似度,除以 防止结果过大:
- Sigmoid激活:生成门控值 将相似度结果输入Sigmoid函数,压缩到0~1区间:。其中若 :静态记忆与上下文高度匹配,门控全开;若 :静态记忆与上下文矛盾或无用,门控关闭。
- 卷积优化:扩展感受野 为提升向量的语境兼容性,引入深度可分离因果卷积(kernel size=4,dilation=最大N-gram阶数)和SiLU激活:。 为所有token的门控后向量 ; - 残差连接确保不丢失原始记忆信息。
2.2.4 与多分支架构的集成(Integration with Multi-branch Architecture)
兼容复杂主干,平衡效率与表达 Engram默认适配多分支Transformer主干(如mHC架构,M=4分支)——这类架构通过并行分支捕捉不同类型特征(局部细节、全局语义),但需解决“参数冗余”问题,核心是“参数共享+分支定制”。
分支专属门控计算:对第m个分支的隐藏状态 ,执行以下流程:
核心:不同分支通过独立的 ,对同一静态记忆 做出差异化评估——比如“科技分支”更关注“苹果公司”,“生活分支”更关注“苹果水果”。
硬件效率优化 将“1个共享 + M个独立 ”的线性投影,融合成单精度FP8的稠密矩阵乘法——适配现代GPU的并行计算特性,提升计算利用率,避免多分支导致的效率损耗。
2.2.5 系统效率:计算与内存解耦(System Efficiency: Decoupling Compute and Memory)
Engram的超大嵌入表(如100B参数)无法仅靠GPU HBM存储,核心解决方案是“算法-硬件协同优化”——将存储与计算分离,利用主机内存/SSD扩展容量,同时通过预取、缓存掩盖延迟。
训练阶段:GPU分片存储+All-to-All通信
嵌入表分片:将Engram的嵌入表按行拆分,分散存储在多个GPU上,容量随GPU数量线性扩展;利用前向传播算法,通过All-to-All通信原语,快速聚合各GPU分片上的激活嵌入行;然后通过反向传播:将梯度通过All-to-All通信分发回对应GPU,完成参数更新。
推理阶段:主机内存预取+通信-计算重叠
嵌入表卸载:将嵌入表迁移到主机内存(TB级容量)或NVMe SSD,不占用GPU HBM;Engram的检索索引由输入token序列决定,可提前解析,主机异步预取嵌入向量;GPU执行前一层计算时,主机同步传输下一层所需嵌入向量,通信与计算并行,掩盖PCIe传输延迟; Engram插入早期层(如Layer 2、15)——既满足模型性能需求(早期卸载静态重建),又能利用前一层计算时间预取。
多级缓存:利用Zipfian分布优化延迟
语言N-gram遵循“少数高频、多数低频”的Zipfian分布,据此设计三级缓存:
- 一级缓存(GPU HBM):缓存Top 10%高频N-gram,延迟最低;
- 二级缓存(主机DRAM):缓存中高频N-gram,快速传输;
- 三级缓存(NVMe SSD):存储低频长尾N-gram,容量大、成本低。
-
2.3 缩放定律与稀疏分配
本章核心是回答两个关键问题:
- 固定参数和计算量下,MoE专家与Engram内存的稀疏容量该如何分配?
- 若无限扩大Engram内存,模型性能会如何变化?
2.3.1 MoE与Engram的最优分配比例
为了让不同分配方案具有可比性,先明确三个核心参数:
- 总参数():模型所有可训练参数(不含词嵌入和输出层),是固定的“参数预算”;
- 激活参数():每个token处理时实际参与计算的参数,决定训练/推理的FLOPs(计算量),保持固定;
- 稀疏参数():未参与实时计算的“闲置参数”(),是可分配的核心资源——MoE中是未被选中的专家参数,Engram中是未被检索的嵌入表参数。
分配比例的量化定义
用分配比例 表示“稀疏参数中分配给MoE的比例”,公式为:。
- :纯MoE模型(所有稀疏参数都给MoE专家);
- :纯Engram模型(所有稀疏参数都给Engram嵌入表);
- :混合模型(部分给MoE,部分给Engram)。
实验设计
- 两个计算预算:覆盖不同模型规模,验证结论通用性——低预算(2e20 FLOPs,5.7B总参数)、高预算(6e20 FLOPs,9.9B总参数);
- 固定稀疏比:所有模型的 (稀疏参数是激活参数的9倍),保证可分配资源规模一致;
- 唯一变量:仅改变 ,调整MoE专家数和Engram嵌入表大小(减少MoE专家数,释放的参数用于扩大Engram),其他训练条件(数据、超参数)完全一致。
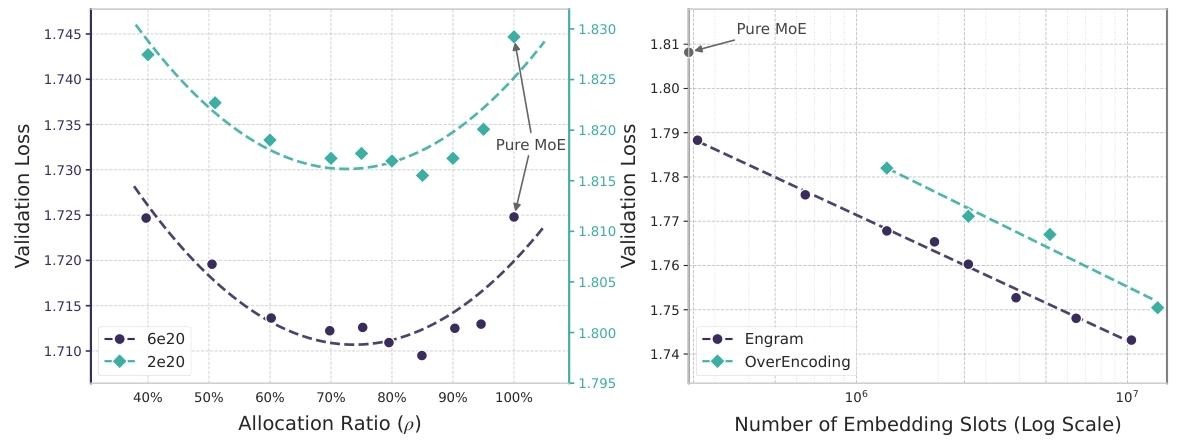
核心发现:U形缩放定律
实验结果显示,验证损失与分配比例 呈明显U形关系(如图3左): 纯MoE()和纯Engram()性能都较差;而最优分配比例:(75%-80%稀疏参数给MoE,20%-25%给Engram);在高预算场景(9.9B参数)下,最优分配的验证损失从1.7248降至1.7109,显著优于纯MoE。
U形曲线的本质原因
- 纯MoE():缺乏专门的静态记忆,需用多层计算模拟知识检索,浪费计算资源;
- 纯Engram():缺乏动态计算能力,无法处理复杂推理(如数学推导),记忆无法替代计算;
- 混合分配:MoE负责动态推理,Engram负责静态检索,适配语言建模的二元需求,实现结构互补。
-
2.3.2 无限内存场景下的Engram缩放
这一节聚焦“解除内存限制后的性能变化”,验证Engram作为独立稀疏轴的无限扩展能力。
实验设计(聚焦内存缩放的纯影响)
- 固定基础架构:3B参数MoE主干(激活参数568M),训练100B tokens确保收敛,主干计算量、参数完全固定;
- 仅扩展Engram:不断增加Engram嵌入表的“嵌入槽数量”(从2.58e5到1e7),Engram参数从少量增至13B,总模型参数增加但激活参数不变(无额外计算量);
- 对比基线:选择OverEncoding(另一种N-gram嵌入扩展方法),确保对比公平。
核心发现:对数线性缩放
实验结果显示(如图3右):随着Engram嵌入槽数量(内存规模)增加,验证损失呈“严格对数线性下降”——内存每扩大一个数量级,损失按固定比例降低,且无饱和迹象;同样扩大内存,Engram的损失下降幅度远大于OverEncoding,证明其“现代化N-gram设计”更能发挥大内存价值; 所有内存扩展都未增加每token的计算量,突破了传统模型“性能提升依赖计算量”的瓶颈。
-
2.4 大规模预训练(Large Scale Pre-training)
本章核心是将Engram架构与稀疏分配定律落地到多十亿参数级模型,通过严格控制变量的大规模预训练实验,验证Engram在真实大模型场景下的有效性——证明其在同参数、同计算量下超越纯MoE模型,且能通过进一步扩展内存持续提升性能。
2.4.1 实验设计
模型配置:4个对比模型,统一激活参数。所有模型均训练2620亿tokens,激活参数严格固定为3.8B(确保同计算量),仅调整总参数分配和架构,具体配置如下:
| 模型名称 | 总参数 | 核心架构差异 | Engram 参数 | MoE 专家配置(共享 + 路由,top-k) |
|---|---|---|---|---|
| Dense-4B | 4.1B | 纯稠密模型(无 MoE、无 Engram),作为基础基线 | 0 | - |
| MoE-27B | 26.7B | 纯 MoE 模型,无 Engram | 0 | 2+72(top-6) |
| Engram-27B | 26.7B | 与 MoE-27B 同参数( iso-parameter),按最优分配比例调整:路由专家从 72 减至 55,释放参数给 Engram | 5.7B | 2+55(top-6) |
| Engram-40B | 39.5B | 保持激活参数不变,进一步扩大 Engram 内存(验证缩放潜力) | 18.5B | 2+55(top-6) |
主干架构:所有模型采用30层Transformer,隐藏层维度2560,集成Multi-head Latent Attention(MLA)和mHC多分支连接(扩展率4)
训练数据:统一使用2620亿tokens的训练语料,分词器为DeepSeek-v3(词汇量128k);
优化器:主干参数用Muon优化器,Engram嵌入参数用Adam优化器(学习率×5,无权重衰减),卷积参数初始化为0(保证训练初期不干扰主干);
Engram具体配置:插入在第2、15层,最大N-gram为3,哈希头数8,嵌入维度1280。
评估基准:覆盖全场景能力
- 语言建模:The Pile测试集损失、验证集损失;
- 知识与推理:MMLU、CMMLU、ARC-Easy/Challenge、BBH等;
- 阅读理解:DROP、RACE(Middle/High)、C3等;
- 代码与数学:HumanEval、MBPP、GSM8K、MATH等;
- 多语言与综合:AGIEval、TriviaQA(中英文)、PopQA等。
2.4.2 核心实验结果
基础性能:同参数下Engram-27B碾压MoE-27B
- 语言建模损失:Engram-27B的Pile损失(1.950)、验证集损失(1.622)均低于MoE-27B(1.960/1.634),证明静态记忆提升了基础语言建模能力;
- 知识类任务:MMLU(+3.0)、CMMLU(+4.0)、MMLU-Pro(+1.8),符合Engram“静态记忆辅助知识检索”的直觉;
- 推理类任务:提升更显著——BBH(+5.0)、ARC-Challenge(+3.7)、DROP(+3.3),验证了“释放主干深度用于推理”的机制;
- 代码/数学类:HumanEval(+3.0)、GSM8K(+2.2)、MATH(+2.4),说明静态记忆能辅助公式、代码模式的识别与生成。
进一步扩大Engram内存(从5.7B增至18.5B),总参数达39.5B,激活参数仍保持3.8B(无额外计算量);其性能表现:Pile损失降至1.942,验证集损失1.610,多数任务性能继续提升(如ARC-Challenge达76.4、CMMLU达63.4);训练末期Engram-40B与基线的损失差距仍在扩大,说明更大的内存容量在当前token预算下尚未完全发挥作用,后续增加训练 tokens 可能进一步提升。
对比稠密模型:稀疏架构的绝对优势 所有稀疏模型(MoE-27B、Engram-27B/40B)均大幅超越同计算量的Dense-4B——例如MMLU从48.6提升至60.4(Engram-27B),ARC-Challenge从59.3提升至73.8,证明稀疏架构的缩放效率远高于稠密模型,而Engram在稀疏架构中进一步优化了性能上限。

-
2.5 长上下文训练(Long Context Training)
本章核心是验证Engram的长上下文处理优势——通过将模型上下文窗口扩展到32k tokens,证明Engram能显著提升长文本中的全局关联捕捉和信息检索能力。核心逻辑是:Engram将局部依赖交给静态查找,释放注意力机制专注于全局上下文,最终在长文本任务中大幅超越纯MoE基线。
2.5.1 实验设计:严格控制变量,聚焦架构差异
长上下文扩展方法:采用YaRN(一种高效的上下文窗口扩展技术),在预训练后新增“32k tokens长上下文训练阶段”
训练数据:300亿tokens的高质量长文本数据;
关键参数:scale=10、α=1、β=32、缩放因子f=0.707;
所有模型使用完全相同的扩展流程,确保对比公平。
模型配置:4组对比模型,隔离关键变量 选取4个模型版本,核心是通过“预训练步数”控制基础模型质量,仅保留架构差异(MoE vs Engram):
| 模型名称 | 预训练步数 | 预训练损失 | 核心特点 |
|---|---|---|---|
| MoE-27B(基线) | 50k | 1.63 | 纯 MoE 架构,完全训练成熟的基线模型 |
| Engram-27B(82% 计算) | 41k | 1.66 | 仅用基线 82% 的预训练计算量(41k vs 50k),验证效率优势 |
| Engram-27B(同损失) | 46k | 1.63 | 预训练损失与基线一致(1.63),严格隔离 “基础模型质量” 干扰,聚焦架构差异 |
| Engram-27B(完全训练) | 50k | 1.62 | 与基线相同预训练步数,验证完全训练后的最优性能 |
评估基准:覆盖长上下文核心能力 选用2类关键基准,全面评估长文本处理能力:
- LongPPL(长文本困惑度):衡量模型对长文本的语言建模能力,包含4类数据(书籍、论文、代码、长链推理CoT);
- RULER(长上下文检索与推理基准):包含8类任务,核心考察“长文本中的信息定位与关联”(如多查询针寻物、变量跟踪、问答等)。
2.5.2 核心实验结果
即使计算量更少,Engram仍具竞争力 Engram-27B(41k步,仅82%计算量):
- LongPPL:与完全训练的MoE-27B(50k步)性能相当(如书籍类4.37 vs 4.38);
- RULER:显著超越基线,尤其是复杂检索任务(如多查询针寻物MQ:89.5 vs 84.2,变量跟踪VT:83.2 vs 77.0)。
- 关键结论:Engram的架构优势,能部分抵消预训练计算量的不足,证明其长上下文处理的高效性。
同损失控制下,架构优势完全凸显 Engram-27B(46k步,预训练损失=1.63,与基线一致):
- LongPPL:全类别优化(书籍4.19 vs 4.38、论文2.84 vs 2.91、代码2.45 vs 2.49);
- RULER:核心任务大幅领先,多查询针寻物MQ达97.0(基线84.2),变量跟踪VT达87.2(基线77.0),问答QA达37.5(基线34.5)。
- 关键结论:排除基础模型质量干扰后,Engram的架构设计是长上下文性能提升的直接原因。
完全训练后,优势进一步扩大 Engram-27B(50k步,预训练损失=1.62):
- LongPPL:再创最优(书籍4.14、论文2.82、代码2.44),长链推理CoT困惑度13.41(基线14.16);
- RULER:8类任务全面第一,多查询MQ保持97.0,变量跟踪VT达89.0,高频词提取FWE达99.3(基线73.0)。
- 关键结论:完全训练后,Engram的长上下文优势完全释放,在“局部依赖卸载+全局注意力聚焦”的双重作用下,实现长文本处理的全面超越。

-
Engram长上下文优势的本质
- 注意力资源的优化分配:纯MoE模型:注意力机制需同时处理“局部依赖(如短语、实体)”和“全局关联(如跨段落逻辑)”,资源被分散;Engram模型:局部依赖通过静态查找直接解决,注意力无需浪费在简单的局部模式重建上,可专注于长文本中的全局逻辑、跨句关联等复杂任务——这是长上下文性能提升的核心原因。
- 长上下文性能与基础模型能力的耦合: - 实验发现:Engram的长上下文性能随预训练步数增加而单调提升(41k→46k→50k),说明长文本处理能力与基础模型的通用建模能力紧密相关;但“同损失”实验证明:即使基础模型能力一致,Engram的架构仍能带来显著提升,说明其优势是“通用能力+架构优化”的双重结果。
- 工程优化的支撑: - Engram的“计算与内存解耦”设计,让长上下文训练时的内存压力大幅降低——32k tokens的长序列无需额外占用GPU HBM存储静态记忆,确保训练高效进行; 确定性预取机制让长上下文推理时的内存读取延迟被掩盖,不影响吞吐量。
-
2.6 分析(Analysis)
本章核心是通过机制解读、架构消融、效率验证三大维度,拆解Engram的性能提升根源、关键组件价值和工程落地可行性,回答“Engram为什么有效”“哪些设计不可或缺”“实际部署效率如何”三大核心问题。
2.6.1 Engram是否等效于增加模型深度?
核心结论:是——Engram通过卸载早期层的静态知识重建任务,让Transformer主干的“有效深度”显著提升,相当于间接增加了模型的推理层数。
问题背景:传统LLM需消耗多层注意力和前馈网络,才能从连续token中拼接出静态实体(如“戴安娜王妃”需6层计算才能完整识别,原文表3)。Engram的核心假设是:用静态查找替代这一过程,可让早期层直接跳过“实体重建”,聚焦更复杂的特征学习,从而等效加深模型的有效推理深度。
验证工具与实验设计:
- 工具1:LogitLens——通过将各层隐藏态投影到输出层,计算与最终预测的KL散度,衡量“该层是否已形成足够成熟的预测”;
- 工具2:CKA(Centered Kernel Alignment)——计算不同模型层的表征相似度,量化Engram层与MoE层的功能对应关系; - 数据:Few-NERD数据集(命名实体识别任务),聚焦实体token的隐藏态分析。
关键发现
- 加速预测收敛(LogitLens结果):Engram模型的早期层KL散度显著低于MoE基线(图4a),说明其在更早的层就完成了“预测就绪”的表征——无需多层计算重建静态知识,预测收敛速度更快;
- 有效深度提升(CKA结果):Engram的浅层表征与MoE的深层表征高度相似(图4b、c)——例如Engram第5层的表征,与MoE第12层的相似度最高。通过“软对齐指数”计算,Engram多数层的“等效MoE深度”均大于自身实际层数,证明其确实通过卸载静态任务,间接加深了模型的有效推理深度。

-
2.6.2 结构消融与层位置敏感性
核心结论:Engram的性能依赖“多分支融合、分词器压缩、上下文门控”三大关键组件,且早期层插入(Layer 2)效果最优。
实验设置
- 基线模型:3B参数MoE模型(激活参数568M),验证损失1.808;
- 测试模型:在基线基础上添加1.6B参数的Engram模块,通过“层位置调整”和“组件删减”进行消融,对比验证损失变化。
| 消融配置 | 验证损失 | 性能变化分析 |
|---|---|---|
| 移除多分支融合 | 1.778 | 性能下降最显著 —— 证明 “分支专属门控” 能让静态记忆适配不同分支的特征需求,提升表达能力 |
| 移除分词器压缩 | 1.775 | 语义冗余增加,检索效率降低,导致损失上升 |
| 移除上下文门控 | 1.773 | 无法抑制哈希冲突和语境不匹配的噪声,静态记忆引入干扰 |
| 移除轻量级卷积 | 1.770 | 影响较小 —— 卷积仅用于扩展感受野,核心功能仍由 “检索 + 门控” 支撑 |
| 增加 4-gram(替代 2/3-gram) | 1.769 | 略有下降 —— 固定参数预算下,4-gram 稀释了高频 2/3-gram 的容量,性价比更低 |
将Engram拆分为两个模块,分别插入Layer 2和Layer 6,验证损失降至1.768(最优)——既通过早期插入卸载静态任务,又通过深层插入补充语境适配,平衡了“卸载效率”和“语境兼容性”。

-
2.6.3 功能敏感性分析:Engram到底负责什么?
核心结论:Engram是事实知识的核心存储载体,但对上下文依赖型任务(如阅读理解)影响极小,功能边界清晰。
实验设计:在推理时完全抑制Engram的输出(仅保留主干网络),对比“有/无Engram”的性能差距,聚焦“事实知识”和“阅读理解”两类极端任务(信号噪声比最高)。
关键发现(图6)
- 事实知识任务:性能灾难性下降,仅保留29%-44%的原始性能(如TriviaQA仅29%)——证明Engram是模型存储“静态事实”(如实体属性、专有名词关联)的核心模块,主干网络难以单独支撑事实检索;
- 阅读理解任务:性能基本保留(81%-93%,如C3达93%)——说明这类任务依赖“上下文关联”和“逻辑推理”,主要由主干的注意力机制支撑,Engram仅起辅助作用。
结论:Engram与主干网络的功能分工明确:Engram负责“静态事实存储与快速检索”,主干负责“动态上下文推理与逻辑关联”,两者各司其职、互补协同。

-
2.6.4 系统效率:推理吞吐量验证
核心结论:Engram的“确定性寻址”设计,使其能高效卸载至主机内存,推理吞吐量损失<3%,工程可行性极强。
实验设置
- 基础模型:4B和8B稠密模型(避免MoE路由的通信干扰);
- Engram配置:添加100B参数的Engram模块,嵌入表完全卸载至主机内存(CPU内存);
- 推理优化:利用Engram的确定性索引,在GPU执行前一层计算时,主机异步预取下一层所需嵌入向量,实现“通信-计算重叠”;
- 硬件:NVIDIA H800 GPU,测试512条序列(长度100-1024)的吞吐量。
关键分析
- 损失率极低(<3%):证明“通信-计算重叠”和“确定性预取”有效掩盖了主机内存的读取延迟,几乎不影响推理效率;
- 优势:100B参数的Engram无需占用GPU HBM(仅80GB左右),突破了GPU内存限制——若用MoE实现同等参数扩展,需大幅增加专家数,且动态路由会导致更高的通信开销。

-
2.6.5 案例研究:门控机制可视化
核心结论:上下文门控能精准识别静态模式(命名实体、固定短语、成语),在这些场景下主动激活,验证了设计初衷。
实验设计:可视化Engram-27B的门控值(0~1,值越大表示静态记忆激活越强),分析不同语言(英、中)和文本类型的激活模式。
关键发现(图7)
- 英文场景:门控在多token实体(“Alexander the Great”“Diana Princess of Wales”)、固定短语(“By the way”“the Milky Way”)处显著激活(红色热图);
- 中文场景:门控在成语(“四大发明”)、历史人物(“张仲景”)、固定表述(“伤寒杂病论”)处强烈激活;
- 门控仅在“静态、固定、高频重复”的语言模式上激活,在自由生成的推理文本或动态语境中保持低激活——完全符合“按需调用静态记忆”的设计目标。

-
-
3.代码详解
3.1 环境安装
推荐使用Python3.8,然后运行:
pip install torch numpy transformers sympy
然后运行:
python engram_demo_v1.py-
3.2 代码
设置
# 源码约38行
@dataclass
class EngramConfig:
tokenizer_name_or_path: str = "deepseek-ai/DeepSeek-V3" # 词元化器路径
engram_vocab_size: List[int] = field(default_factory=lambda: [129280*5, 129280*5]) # 词汇表大小(默认为129280×5的两倍)
max_ngram_size: int = 3 # 最大n-gram大小为3
n_embed_per_ngram: int = 512 # 每n-gram嵌入维度512
n_head_per_ngram: int = 8 # 注意力头数8
layer_ids: List[int] = field(default_factory=lambda: [1, 15]) # 层ID列表[1,15]
pad_id: int = 2
seed: int = 0
kernel_size: int = 4
@dataclass
class BackBoneConfig:
hidden_size: int = 1024 # 配置隐藏层大小1024
hc_mult: int = 4 # 隐藏通道倍数4
vocab_size: int = 129280 # 词汇表大小129280
num_layers: int = 30 # 层数30
engram_cfg = EngramConfig()
backbone_config = BackBoneConfig()这段代码构建了一个语言模型架构,包含词嵌入层、多个Transformer块和输出线性层。代码对输入文本进行tokenization后,依次通过各层:首先词嵌入转换为隐藏状态,然后模拟超连接扩展维度,最后通过Transformer块处理并输出结果。
# 源码约396行
if __name__ == '__main__':
LLM = [
nn.Embedding(backbone_config.vocab_size,backbone_config.hidden_size), # 129280->1024
*[TransformerBlock(layer_id=layer_id) for layer_id in range(backbone_config.num_layers)],
nn.Linear(backbone_config.hidden_size, backbone_config.vocab_size) # 1024->129280
]
text = "Only Alexander the Great could tame the horse Bucephalus."
tokenizer = AutoTokenizer.from_pretrained(engram_cfg.tokenizer_name_or_path,trust_remote_code=True)
input_ids = tokenizer(text,return_tensors='pt').input_ids # [b,seq_len]=[1,14]
B,L = input_ids.shape
for idx, layer in enumerate(LLM):
if idx == 0:
hidden_states = LLM[0](input_ids) # [1,14]->[1,14,1024]
## mock hyper-connection
hidden_states = hidden_states.unsqueeze(2).expand(-1, -1, backbone_config.hc_mult, -1) # [1,14,1024]->[1,14,4,1024]
elif idx == len(LLM)-1:
## mock hyper-connection
hidden_states = hidden_states[:,:,0,:]
output = layer(hidden_states)
else:
hidden_states = layer(input_ids=input_ids,hidden_states=hidden_states)
print("✅ Forward Complete!")
print(f"{input_ids.shape=}
{output.shape=}")-
TransformerBlock()
这段代码定义了一个Transformer块,包含注意力机制、MoE(混合专家)和记忆增强模块。初始化时根据层ID决定是否启用记忆模块(即Engram)。本演示代码将注意力、MoE部分进行了简化,故我们只看Engram部分。
class TransformerBlock(nn.Module):
def __init__(self,layer_id):
super().__init__()
self.attn = lambda x:x
self.moe = lambda x:x
self.engram = None
if layer_id in engram_cfg.layer_ids:
self.engram = Engram(layer_id=layer_id)
def forward(self,input_ids,hidden_states):
if self.engram is not None:
hidden_states = self.engram(hidden_states=hidden_states,input_ids=input_ids) + hidden_states
hidden_states = self.attn(hidden_states) + hidden_states
hidden_states = self.moe(hidden_states) + hidden_states
return hidden_states-
Engram
class Engram(nn.Module):
def __init__(self,layer_id):
super().__init__()
self.layer_id = layer_id
self.hash_mapping = NgramHashMapping( # 创建Ngram哈希映射模块处理词汇表映射(参照架构图,为下方的Hash)
engram_vocab_size=engram_cfg.engram_vocab_size,
max_ngram_size = engram_cfg.max_ngram_size,
n_embed_per_ngram = engram_cfg.n_embed_per_ngram,
n_head_per_ngram = engram_cfg.n_head_per_ngram,
layer_ids = engram_cfg.layer_ids,
tokenizer_name_or_path=engram_cfg.tokenizer_name_or_path,
pad_id = engram_cfg.pad_id,
seed = engram_cfg.seed,
)
self.multi_head_embedding = MultiHeadEmbedding( # 构建多头嵌入层进行特征表示(参照架构图,为下方的两个Embedding)
list_of_N = [x for y in self.hash_mapping.vocab_size_across_layers[self.layer_id] for x in y],
D = engram_cfg.n_embed_per_ngram // engram_cfg.n_head_per_ngram,
)
self.short_conv = ShortConv( # 初始化短卷积层处理序列信息(参照架构图,为上方的Conv)
hidden_size = backbone_config.hidden_size,
kernel_size = engram_cfg.kernel_size,
dilation = engram_cfg.max_ngram_size,
hc_mult = backbone_config.hc_mult,
)
engram_hidden_size = (engram_cfg.max_ngram_size-1) * engram_cfg.n_embed_per_ngram
self.value_proj = nn.Linear(engram_hidden_size,backbone_config.hidden_size) #(参照架构图,为右边的Linear)
self.key_projs = nn.ModuleList( #(参照架构图,为左边的Linear)
[nn.Linear(engram_hidden_size,backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)]
)
self.norm1 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)])
self.norm2 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)])
def forward(self,hidden_states,input_ids):
"""
hidden_states: [B, L, HC_MULT, D]
input_ids: [B, L]
"""
hash_input_ids = torch.from_numpy(self.hash_mapping.hash(input_ids)[self.layer_id]) # [b,seq_len]=[1,14]->[b,seq_len,N]=[1,14,16]
embeddings = self.multi_head_embedding(hash_input_ids).flatten(start_dim=-2) # [b,seq_len,hidden_size]=[1,14,1024]
gates = []
for hc_idx in range(backbone_config.hc_mult):
key = self.key_projs[hc_idx](embeddings) # [b,seq_len,hidden_size]=[1,14,1024]
normed_key = self.norm1[hc_idx](key) # [b,seq_len,hidden_size]=[1,14,1024]
query = hidden_states[:,:,hc_idx,:] # [b,seq_len,hidden_size]=[1,14,1024]
normed_query = self.norm2[hc_idx](query)
gate = (normed_key * normed_query).sum(dim=-1) / math.sqrt(backbone_config.hidden_size) # # [b,seq_len]=[1,14]
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign() # 对门值取绝对值后限制最小值为1e-6避免数值过小,然后开平方根增强非线性,最后乘以原符号保持正负性,确保门控信号既有幅度约束又保留原始方向信息。
gate = gate.sigmoid().unsqueeze(-1) # [b,seq_len,1]=[1,14,1]
gates.append(gate)
gates = torch.stack(gates,dim=2) # [b,seq_len,4,1]=[1,14,4,1]
value = gates * self.value_proj(embeddings).unsqueeze(2) # [b,seq_len,4,hidden_size]=[1,14,4,1024]
output = value + self.short_conv(value) # [b,seq_len,4,hidden_size]=[1,14,4,1024]
return output NgramHashMapping
NgramHashMapping类是一个用于生成不同层、不同 N 元语法(ngram)哈希映射的工具类,核心功能是基于压缩后的 token ID,为不同网络层生成唯一的 N 元语法哈希值,且每个哈希头使用不同的素数作为模数,保证哈希分布的唯一性。
class NgramHashMapping:
def __init__( # 一个用于生成不同层、不同 N 元语法(ngram)哈希映射的工具类,核心功能是基于压缩后的 token ID,为不同网络层生成唯一的 N 元语法哈希值,且每个哈希头使用不同的素数作为模数,保证哈希分布的唯一性。
self,
engram_vocab_size,
max_ngram_size,
n_embed_per_ngram,
n_head_per_ngram,
layer_ids,
tokenizer_name_or_path,
pad_id,
seed,
):
self.vocab_size_per_ngram = engram_vocab_size
self.max_ngram_size = max_ngram_size
self.n_embed_per_ngram = n_embed_per_ngram
self.n_head_per_ngram = n_head_per_ngram
self.pad_id = pad_id
self.layer_ids = layer_ids
self.compressed_tokenizer = CompressedTokenizer(
tokenizer_name_or_path=tokenizer_name_or_path
)
self.tokenizer_vocab_size = len(self.compressed_tokenizer)
if self.pad_id is not None:
self.pad_id = int(self.compressed_tokenizer.lookup_table[self.pad_id])
max_long = np.iinfo(np.int64).max
M_max = int(max_long // self.tokenizer_vocab_size)
half_bound = max(1, M_max // 2)
PRIME_1 = 10007
self.layer_multipliers = {}
for layer_id in self.layer_ids:
base_seed = int(seed + PRIME_1 * int(layer_id))
g = np.random.default_rng(base_seed)
r = g.integers(
low=0,
high=half_bound,
size=(self.max_ngram_size,),
dtype=np.int64
)
multipliers = r * 2 + 1
self.layer_multipliers[layer_id] = multipliers
self.vocab_size_across_layers = self.calculate_vocab_size_across_layers()
def calculate_vocab_size_across_layers(self):
seen_primes = set() # 记录已使用的素数,避免重复
vocab_size_across_layers = {} # 存储每层、每个ngram头的素数模数
for layer_id in self.layer_ids:
all_ngram_vocab_sizes = [] # 存储当前层所有ngram的头模数
for ngram in range(2, self.max_ngram_size + 1): # 遍历2-gram到max_ngram
current_ngram_heads_sizes = [] # 当前ngram的所有头模数
# 获取当前ngram的基础词汇表大小
vocab_size = self.vocab_size_per_ngram[ngram - 2]
num_head = self.n_head_per_ngram # 每个ngram的头数量
current_prime_search_start = vocab_size - 1 # 素数查找起始值
for _ in range(num_head): # 为每个头分配唯一的素数
found_prime = find_next_prime( # 查找下一个未使用的素数(find_next_prime是外部函数,需实现)
current_prime_search_start,
seen_primes
)
seen_primes.add(found_prime) # 标记为已使用
current_ngram_heads_sizes.append(found_prime)
current_prime_search_start = found_prime # 更新下一次查找起点
all_ngram_vocab_sizes.append(current_ngram_heads_sizes)
vocab_size_across_layers[layer_id] = all_ngram_vocab_sizes
return vocab_size_across_layers
def _get_ngram_hashes( # N元语法哈希映射
self,
input_ids: np.ndarray,
layer_id: int,
) -> np.ndarray:
x = np.asarray(input_ids, dtype=np.int64) # 转换为int64数组,输入形状:[B, T](B=批量大小,T=序列长度)
B, T = x.shape
multipliers = self.layer_multipliers[layer_id] # 获取当前层的乘法因子
def shift_k(k: int) -> np.ndarray: # 定义移位函数:生成k步移位的token序列(用于构建N元语法)
if k == 0: return x
shifted = np.pad(x, ((0, 0), (k, 0)), # 向左移位k步,右侧补pad_id(比如k=1时,序列[1,2,3]变为[pad,1,2])
mode='constant', constant_values=self.pad_id)[:, :T]
return shifted
base_shifts = [shift_k(k) for k in range(self.max_ngram_size)] # 生成0到max_ngram_size-1步的移位序列(比如max=3时,生成0/1/2步移位)
all_hashes = [] # 存储所有头的哈希结果
for n in range(2, self.max_ngram_size + 1): # 遍历2-gram到max_ngram
n_gram_index = n - 2 # 转换为0起始索引(2-gram=0,3-gram=1...)
tokens = base_shifts[:n] # 取前n个移位序列(比如2-gram取0/1步移位,3-gram取0/1/2步移位)
mix = (tokens[0] * multipliers[0]) # 初始化哈希混合值:第一个token * 第一个乘法因子
for k in range(1, n): # 后续token与当前mix做异或(XOR)运算(保证顺序敏感)
mix = np.bitwise_xor(mix, tokens[k] * multipliers[k])
num_heads_for_this_ngram = self.n_head_per_ngram # 当前ngram的头数量
head_vocab_sizes = self.vocab_size_across_layers[layer_id][n_gram_index] # 当前ngram所有头的素数模数
for j in range(num_heads_for_this_ngram): # 为每个头计算哈希值(取模)
mod = int(head_vocab_sizes[j])
head_hash = mix % mod # 哈希核心:混合值对素数取模
all_hashes.append(head_hash.astype(np.int64, copy=False))
return np.stack(all_hashes, axis=2)最终hash_ids_for_all_layers的结果如下:

代码对应:


-
NgramHash的作用
简单来说:用N-gram加强连续词之间的理解能力。然后使用hash+embedding解决空间爆炸问题。
NgramHash用 “移位 + 顺序敏感哈希” 把连续 N 个词的语义压缩成一个紧凑的 ID,再用 “多头嵌入” 把这个 ID 转化为能被模型学习的特征向量,最终用极低的空间成本,让模型学到连续词之间的局部依赖关系。
什么是Ngram(N元语法)
Ngram是把文本序列拆分成连续的N个Token组成的“片段”,用来捕捉局部上下文关系:
- 2-gram(二元组):比如序列 `[t0, t1, t2, t3]`,拆成 `(t0,t1)、(t1,t2)、(t2,t3)`;
- 3-gram(三元组):拆成 `(t0,t1,t2)、(t1,t2,t3)`;
- 以此类推,直到`max_ngram_size`(比如配置里的3)。
在代码中,Ngram不是直接存储这些元组,而是通过哈希+嵌入的方式,把每个N元组映射成唯一的特征向量,既保留局部上下文信息,又避免存储海量N元组(比如1000词表的3-gram有10亿种组合)。
代码中Ngram的完整实现流程
步骤1:移位构建N元组(核心中的核心)
要生成Ngram,首先要把原始序列做移位对齐,让每个位置能拿到组成N元组的所有Token。
def shift_k(k: int) -> np.ndarray:
if k == 0: return x # 0步移位=原序列
# 向左移位k步,右侧补pad_id(关键操作)
shifted = np.pad(x, ((0, 0), (k, 0)),
mode='constant', constant_values=self.pad_id)[:, :T]
return shifted
# 生成0到max_ngram_size-1步的移位序列(比如max=3时,生成0/1/2步移位)
base_shifts = [shift_k(k) for k in range(self.max_ngram_size)]举个例子(直观理解移位): 假设输入序列x = [t0, t1, t2, t3](形状[1,4]),max_ngram_size=3,pad_id=0:
- shift_k(0) → [t0, t1, t2, t3](0步移位,原序列);
- shift_k(1) → 左边补1个pad → [0, t0, t1, t2](1步移位,每个位置是原序列前1位);
- shift_k(2) → 左边补2个pad → [0, 0, t0, t1](2步移位,每个位置是原序列前2位);
 步骤2:哈希映射(压缩Ngram空间)
步骤2:哈希映射(压缩Ngram空间)
拿到N元组的Token后,不能直接用(组合数太多),需要通过**哈希+取模**把无限的N元组映射到有限的ID空间。
for n in range(2, self.max_ngram_size + 1): # 遍历2-gram、3-gram...
n_gram_index = n - 2
tokens = base_shifts[:n] # 取前n个移位序列(2-gram取前2个,3-gram取前3个)
# 第一步:混合Token ID(保证顺序敏感)
mix = (tokens[0] * multipliers[0]) # 第一个Token * 随机乘法因子
for k in range(1, n):
# 后续Token与当前mix做异或(XOR)→ 顺序不同,mix结果不同
mix = np.bitwise_xor(mix, tokens[k] * multipliers[k])
# 第二步:取模压缩到固定范围(素数模保证分布均匀)
head_vocab_sizes = self.vocab_size_across_layers[layer_id][n_gram_index]
for j in range(num_heads_for_this_ngram):
mod = int(head_vocab_sizes[j]) # 每个头用唯一素数作为模
head_hash = mix % mod # 最终哈希ID
all_hashes.append(head_hash)为什么用「乘法+异或」混合?乘法:给每个Token加“权重”(`multipliers`是每层随机生成的奇数,保证每层哈希规则不同);异或(XOR):是“顺序敏感”的运算 → 比如`(t0,t1)`和`(t1,t0)`的mix结果完全不同,能区分N元组的顺序(这是Ngram的核心,比如“我爱你”和“你爱我”是不同的2-gram)。
为什么用素数取模? 素数作为模数,能让哈希结果的分布更均匀,减少“哈希冲突”(不同N元组映射到同一个ID); 每个头用不同的素数,进一步降低冲突概率,同时让多个头能捕捉不同的Ngram特征。
例子(哈希计算): 还是用shift0=[t0,t1,t2,t3]、shift1=[0,t0,t1,t2](2-gram):
- 位置0:tokens[0]=t0, tokens[1]=0 → mix = t0*mul0 XOR 0*mul1 = t0*mul0 → hash = mix % 素数;
- 位置1:tokens[0]=t1, tokens[1]=t0 → mix = t1*mul0 XOR t0*mul1 → hash = mix % 素数;
- 最终每个位置得到一个2-gram哈希ID,3-gram同理。
步骤3:多头嵌入编码(哈希ID→特征向量) 哈希ID只是数字,需要通过`MultiHeadEmbedding`转化为特征向量,这一步是Ngram特征的最终编码:
# 哈希ID形状:[B, L, N](B=批量,L=序列长度,N=总头数)
hash_input_ids = torch.from_numpy(self.hash_mapping.hash(input_ids)[self.layer_id])
# 多头嵌入:[B, L, N] → [B, L, N, D_head]
embeddings = self.multi_head_embedding(hash_input_ids)
# 展平为最终Ngram特征:[B, L, N*D_head]
embeddings = embeddings.flatten(start_dim=-2)每个Ngram头对应一个独立的嵌入空间(通过偏移量区分),比如2-gram的2个头、3-gram的2个头,共4个头,每个头的嵌入维度是1024//16=64(配置里的n_embed_per_ngram//n_head_per_ngram); 展平后,每个位置的Ngram特征是所有头的嵌入向量拼接,既保留了多视角的Ngram信息,又形成一个统一的特征向量。
解决的核心问题
你可能会问:直接拆N元组、做One-Hot编码不行吗?
答案是:不行,因为: 空间爆炸:
- 1000词表的3-gram有10亿种组合,One-Hot编码根本存不下;
- 泛化性差:训练集中没见过的N元组无法处理;
- 效率低:直接存储N元组会让模型参数量飙升。
而代码中的方案:哈希映射把无限的N元组压缩到有限的ID空间(素数模大小),空间复杂度从O(V^N)降到O(V); 多头嵌入通过共享嵌入表,让相似的N元组(哈希冲突的)学到相似的特征,保证泛化性; 移位+向量化计算全程用numpy/torch的向量化操作,比循环拆分N元组快10倍以上。
-
CompressedTokenizer
这段代码实现了一个CompressedTokenizer类,核心功能是对预训练的 Tokenizer(分词器)进行词汇表压缩,将语义 / 形式上等价的 token ID 映射到同一个新 ID,从而减少 token 的总数量。
class CompressedTokenizer:
def __init__( # 对预训练的 Tokenizer(分词器)进行词汇表压缩,将语义 / 形式上等价的 token ID 映射到同一个新 ID,从而减少 token 的总数量。
self,
tokenizer_name_or_path,
):
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path, trust_remote_code=True)
SENTINEL = ""
self.normalizer = normalizers.Sequence([
normalizers.NFKC(),
normalizers.NFD(),
normalizers.StripAccents(),
normalizers.Lowercase(),
normalizers.Replace(Regex(r"[
]+"), " "),
normalizers.Replace(Regex(r"^ $"), SENTINEL),
normalizers.Strip(),
normalizers.Replace(SENTINEL, " "),
])
self.lookup_table, self.num_new_token = self._build_lookup_table()
def __len__(self):
return self.num_new_token
def _build_lookup_table(self):
old2new = {} # 旧token ID -> 新token ID的映射
key2new = {} # 归一化后的文本key -> 新token ID的映射
new_tokens = [] # 存储压缩后的唯一token文本
vocab_size = len(self.tokenizer) # 获取原分词器的词汇表大小
for tid in range(vocab_size):
text = self.tokenizer.decode([tid], skip_special_tokens=False) # 解码token ID为原始文本(保留特殊token,skip_special_tokens=False)
if "�" in text: # 处理无法解码的乱码字符(�):直接使用token的字符串形式(比如)
key = self.tokenizer.convert_ids_to_tokens(tid)
else:
norm = self.normalizer.normalize_str(text) # 对正常文本进行归一化,得到标准化的key
key = norm if norm else text # 如果归一化后为空(比如全是空格被strip了),则用原文本
nid = key2new.get(key) # 检查该key是否已有对应的新ID
if nid is None: # 无则创建新ID(按顺序分配)
nid = len(new_tokens)
key2new[key] = nid
new_tokens.append(key)
old2new[tid] = nid # 记录旧ID到新ID的映射
lookup = np.empty(vocab_size, dtype=np.int64) # 创建numpy数组形式的查找表(比字典查询更快)
for tid in range(vocab_size):
lookup[tid] = old2new[tid]
return lookup, len(new_tokens)
def _compress(self, input_ids): # 将输入ID数组中大于等于0的有效ID通过查找表进行映射转换,无效的负数ID保持不变。
arr = np.asarray(input_ids, dtype=np.int64)
pos_mask = arr >= 0 # >=0的全为True,创建掩码标识有效位置
out = arr.copy()
valid_ids = arr[pos_mask] # 提取有效ID
out[pos_mask] = self.lookup_table[valid_ids] # 用查找表转换后写回原位置
return out
def __call__(self, input_ids):
return self._compress(input_ids) 压缩结果如下:
arr = [[ 0 22898 19737 270 9327 1494 112253 270 15000 406, 11999 25670 349 16]]
out = [[ 0 1134 15695 237 2049 1260 85761 237 12071 36 9745 20232, 290 16]]class MultiHeadEmbedding(nn.Module):
def __init__(self, list_of_N: List[int], D: int):
super().__init__()
self.num_heads = len(list_of_N) # # 嵌入头的数量(比如[100,200]对应2个头)
self.embedding_dim = D # 嵌入维度
offsets = [0]
for n in list_of_N[:-1]:
offsets.append(offsets[-1] + n) # 计算每个头在总嵌入空间中的偏移位置
self.register_buffer("offsets", torch.tensor(offsets, dtype=torch.long))
total_N = sum(list_of_N)
self.embedding = nn.Embedding(num_embeddings=total_N, embedding_dim=D) # 创建一个总的嵌入表,大小为所有头的词汇表大小之和
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
shifted_input_ids = input_ids + self.offsets # 给每个头的输入ID加上对应的偏移量,区分不同头的ID空间
output = self.embedding(shifted_input_ids) # 查大嵌入表:shifted_input_ids的每个ID对应唯一的嵌入向量
return output # [b,seq_len,N]=[1,14,16]->[b,seq_len,N,embedding_dim=D]=[1,14,16,64]-
CompressedTokenizer的作用
CompressedTokenizer(压缩分词器)是整个流程的前置基础——它先对原始分词器的词汇表做“瘦身”,从源头减少后续Ngram哈希的压力,同时保证语义等价的Token被合并,不丢失关键信息。
核心目标:词汇表“瘦身”+ 语义归一化 原始的预训练分词器(比如BERT的tokenizer)词汇表通常有几万个Token,其中很多Token是“语义等价但形式不同”的:
- 大小写不同:`Hello` 和 `hello`;
- 带重音/不带重音:`café` 和 `cafe`;
- 空白符不同:`a b`(两个空格)和 `a b`(一个空格);
- 全角/半角:`123` 和 `123`。
CompressedTokenizer的核心目标就是:
- 归一化:把这些“形式不同、语义相同”的Token统一成同一个表示;
- 压缩:基于归一化结果,将原始大词汇表映射为更小的词汇表,减少后续哈希/嵌入的计算量;
- 兼容:保留所有Token的映射关系,输入原始Token ID能无缝转换为压缩后的ID。
实现逻辑
CompressedTokenizer`的代码逻辑可以拆成两个核心步骤,我们逐行拆解关键操作:
步骤1:定义文本归一化规则,这是压缩的“判断标准”——决定哪些Token该被合并。
# 初始化函数中的归一化流水线
self.normalizer = normalizers.Sequence([
normalizers.NFKC(), # 统一字符形式:全角→半角、兼容字符→标准字符(比如1→1)
normalizers.NFD(), # 分解带重音的字符:café → ca fé(基础字符+重音标记)
normalizers.StripAccents(), # 移除重音标记:ca fé → cafe
normalizers.Lowercase(), # 全部小写:Hello → hello
normalizers.Replace(Regex(r"[
]+"), " "), # 多个空白符→单个空格:a b → a b
normalizers.Replace(Regex(r"^ $"), SENTINEL), # 特殊处理:仅单个空格→临时哨兵(避免被Strip移除)
normalizers.Strip(), # 移除首尾空格: hello → hello
normalizers.Replace(SENTINEL, " "), # 哨兵还原:单个空格保留
])核心效果:任何“语义相同、形式不同”的文本,经过这个流水线后,都会变成完全一样的字符串。 比如:`Café World` → 归一化后 → `cafe world`;`cafe world` → 归一化后 → `cafe world`。
步骤2:构建原始ID→压缩ID的映射表(_build_lookup_table)
这是压缩的“执行动作”——基于归一化结果,为每个原始Token分配唯一的压缩ID。
def _build_lookup_table(self):
old2new = {} # 原始Token ID → 压缩后ID
key2new = {} # 归一化后的文本 → 压缩后ID(核心:相同key对应同一个ID)
new_tokens = []
# 遍历原始分词器的所有Token ID
vocab_size = len(self.tokenizer)
for tid in range(vocab_size):
# 步骤2.1:解码原始Token ID为文本(保留特殊Token:/等)
text = self.tokenizer.decode([tid], skip_special_tokens=False)
# 步骤2.2:处理乱码Token(无法正常解码的�)
if "�" in text:
key = self.tokenizer.convert_ids_to_tokens(tid) # 用Token的字符串名(比如)
else:
# 对正常文本做归一化,得到统一的key
norm = self.normalizer.normalize_str(text)
key = norm if norm else text # 归一化后为空则用原文本(比如空字符串)
# 步骤2.3:分配压缩ID(相同key→同一个ID)
nid = key2new.get(key)
if nid is None: # 首次出现的key,分配新ID
nid = len(new_tokens)
key2new[key] = nid
new_tokens.append(key)
old2new[tid] = nid # 记录原始ID到压缩ID的映射
# 步骤2.4:转为numpy数组(批量查询更快)
lookup = np.empty(vocab_size, dtype=np.int64)
for tid in range(vocab_size):
lookup[tid] = old2new[tid]
return lookup, len(new_tokens) 步骤3:压缩函数(_compress)——实际使用映射表
def _compress(self, input_ids):
arr = np.asarray(input_ids, dtype=np.int64)
pos_mask = arr >= 0 # 只处理有效ID(>=0),负数ID(比如padding的特殊标记)保留
out = arr.copy()
valid_ids = arr[pos_mask] # 提取有效ID
out[pos_mask] = self.lookup_table[valid_ids] # 批量映射为压缩ID
return out输入任意原始Token ID序列(比如`[7592, 2088]`),输出压缩后的ID序列(比如`[123, 456]`),无效ID(负数)保持不变。
实际效果:词汇表“瘦身”的具体例子 以BERT-base-uncased为例: - 原始词汇表大小:30522; - 经过`CompressedTokenizer`后: - 所有大小写、重音、空白符不同的Token被合并; - 压缩后词汇表大小通常能降到1万以内(甚至更低); - 比如原始Token `Hello`(ID=7592)、`hello`(ID=7592,本身小写)、`HELLO`(如果存在),都会被映射到同一个压缩ID。
为什么必须先压缩?
CompressedTokenizer是整个Ngram流程的“前置优化”,没有它,后续的Ngram哈希会面临两个问题:
- 哈希冲突概率飙升:原始词汇表越大,Ngram的组合数越多,哈希冲突(不同N元组映射到同一个ID)的概率越高;压缩后词汇表变小,冲突概率大幅降低;
- 计算效率低下:原始Token ID范围大(3万+),哈希时的乘法/异或操作容易溢出,且嵌入层参数量大;压缩后ID范围小,计算更快、嵌入层参数量更少。
-
-
4.总结
这篇文章聚焦大语言模型中稀疏性设计的优化,提出“条件记忆”作为混合专家模型(MoE)条件计算的补充稀疏轴,通过名为Engram的模块实现静态知识的高效检索与动态融合,以解决传统Transformer缺乏原生知识查找原语、需通过复杂计算模拟检索的低效问题。
Engram模块基于现代化N-gram嵌入设计,整合了分词器压缩、多头哈希、上下文门控、多分支融合等关键组件,先通过分词器压缩降低词汇冗余、提升语义密度,再利用多头哈希对后缀N-gram进行O(1)快速检索,结合上下文门控根据当前语境动态调节静态记忆的权重以抑制噪声,同时适配多分支Transformer主干架构,通过“核心参数共享、分支细节定制”平衡参数效率与表达能力。系统层面,Engram通过训练时GPU分片存储与All-to-All通信、推理时主机内存预取与多级缓存,实现计算与内存的解耦,突破GPU内存限制且推理开销控制在3%以内。
为优化MoE与Engram的容量分配,文章提出稀疏分配问题,通过实验发现U形缩放定律,即固定参数和计算量下,将75%-80%稀疏参数分配给MoE、20%-25%分配给Engram时性能最优,且无限内存场景中Engram性能随内存规模呈对数线性提升。大规模预训练实验中,Engram-27B(26.7B参数)在同参数、同计算量下,不仅在知识检索任务(如MMLU+3.4、CMMLU+4.0)中表现优异,更在通用推理(如BBH+5.0、ARC-Challenge+3.7)、代码/数学(如HumanEval+3.0、MATH+2.4)等复杂任务上显著超越纯MoE基线,Engram-40B进一步扩大内存后性能持续提升。长上下文训练验证了Engram的架构优势,通过卸载局部依赖释放注意力资源聚焦全局上下文,在32k序列长度的LongPPL和RULER基准中全面超越MoE模型,多查询针寻物任务准确率从84.2提升至97.0。
综上,文章证明条件记忆是下一代稀疏模型的关键原语,Engram模块通过架构创新与系统优化,实现了性能与效率的双重提升,为大模型的稀疏化设计提供了新范式。